В идеальном мире маркетолог или владелец бизнеса не только работает с “конверсиями”, но использует для оценки посетителей сайта Customer Lifetime Value (сокращённо CLV) – грубо говоря, это сумма денег, которую принесёт посетитель за всё время, пока будет пользоваться сервисом. Оценка клиентов по CLV является предпочтительной и для мобильных приложений, и для игр, и для любых онлайн сервисов.
Но в реальной жизни всё, конечно, не так, как в идеальном мире. Чтобы рассчитать CLV клиента, нужны исходные данные: средний чек, частота покупок, и время “удержания”, т.е. как долго клиент будет пользоваться сервисом.
- Все эти параметры, во-первых, вообще неизвестны для нового посетителя, который только что пришёл на сайт.
- Во-вторых, параметры “средний чек” и “частота покупок” подразумевают достаточный объем накопленной статистики по каждому клиенту, как минимум 3-5 покупок. В реальной жизни такая статистика накапливается у очень небольшого процента посетителей.
- В третьих, время удержания конкретного клиента заранее неизвестно, а среднее время удержания, рассчитанное по сегменту посетителей, имеет огромную дисперсию: один посетитель перестал заходить на сайт сразу после первого визита (время удержания ноль), второй пользуется в течение двух лет. И каким, например, надо считать время удержания посетителя, который появился на сайте только вчера? (кстати, это интересная тема для следующей статьи).
Всё это делает расчёт CLV для индивидуального посетителя вообще невозможным, а расчёт для сегмента посетителей – крайне ненадёжным, особенно для небольших сегментов, и новых посетителей.
В то же время было бы очень заманчивым использовать CLV, например, для оценки трафика, генерируемого рекламными кампаниями и даже отдельными рекламными объявлениями. Как это сделать?

Как заглянуть в будущее
В предыдущих статьях мы прогнозировали конверсию, которая произойдёт или не произойдет после перехода на сайт. Но ничего не мешает расширить горизонт прогноза, и в буквальном смысле заглядывать в будущее – предсказывать, сколько конверсий будет у посетителя в течение определённого интервала времени, например следующих двух месяцев. Это будет не совсем классический CLV, поскольку прогноз делается для конечного интервала, а не “на всю жизнь”, тем не менее такой прогноз вполне достаточен для решения многих маркетинговых задач. Более того, вместо конверсий можно предсказывать сумму заказов – это уже почти CLV.
В отличие от классического расчёта CLV через предрассчитанные параметры клиентов (удержание, средний чек, частота), прогноз CLV моделью машинного обучения не требует никаких предварительных расчётов и работает на индивидуальном для каждого клиента уровне, что позволяет легко сравнивать клиентов друг с другом и группировать в сегменты по ожидаемой выручке.
Что прогнозируем
Будем считать, что количество конверсий $k$ берётся из распределения Пуассона: $$\Pr(k)=\frac{\lambda^k}{k!}e^{-\lambda}$$ тогда для каждого посетителя надо вычислить его индивидуальный коэффициент $\lambda$, обозначающий ожидаемое количество конверсий за единицу времени (в нашем случае 60 дней). Эта задача известна, как пуассоновская регрессия. В классическом варианте она решается через линейную модель, но можно использовать любые продвинутые алгоритмы: деревья решений, нейросети и т.п.
Построение моделей и оценку качества будем делать на тех же сайтах, что и в предыдущих статьях.
Оценка качества
Качество регрессии традиционно оценивается или через абсолютную ошибку MSE (среднеквадратичная ошибка) или MAE (средняя абсолютная ошибка), или через через относительную ошибку, например MAPE (Mean Absolute Percentage Error). К сожалению, все эти способы подразумевают, что целевая переменная имеет нормальное или близкое к нему распределение, и для нашей задачи не подходят. Поясню на примерах:
Если использовать абсолютную ошибку, то разница между 10 конверсиями и 11 конверсиями будет такой же, как разница между нулём конверсий и одной конверсией. Но с точки зрения бизнеса, ноль конверсий и одна конверсия это большая разница, а 10 и 11 – незначительная.
Если использовать относительную ошибку, то в случае, когда предсказана одна конверсия, а в реальности было ноль конверсий, ошибка станет бесконечной – так тоже не годится. Можно добавлять к истинному значению сглаживающую константу $\epsilon$, чтобы избежать деления на 0, но такая ошибка станет просто абстрактным числом, не имеющим внятной интерпретации.
Более приемлемым вариантом оказалось использование метрики AUC, только для регрессионных задач она называется Concordance index (c-index, c-statistic), и интерпретируется не как площадь под кривой, а как вероятность того, что в парах “прогноз – истинное значение”, относящимся к двум случайно выбранным примерам, прогнозы будут правильно отранжированы. Т.е. если истинное значение в первой паре больше значения во второй паре, то и прогноз из первой пары будет больше прогноза из второй пары.
Concordance index не чувствителен к калибровке прогноза, это тоже важно (вопроса калибровки коснёмся немного позже).
Входные данные
Будем использовать такой же набор признаков, как и в предыдущей модели, за исключением признаков, относящихся к текущему переходу на сайт, т.к. в новой модели нет “текущего” перехода. Т.е. оставим только признаки, относящиеся к истории переходов, к истории сессий, и к посетителю в целом (браузер, гео, устройство и т.п.).
Кроме этого, нужен ещё один признак, играющий в модели важную роль: время с момента последней активности посетителя.
В предыдущих моделях за текущий момент времени принимался момент перехода на сайт. Это было удобным для изучения факторов, влияющих на вероятность конверсии, но прогноз, который выдавала модель, сам по себе не имел практической ценности. В самом деле, какой смысл прогнозировать результат сессии, если можно просто немного подождать, сессия закончится сама собой, и результат будет виден и так?
В новой модели мы прогнозируем количество конверсий для произвольной выборки посетителей, которые были на сайте когда то раньше. Очевидно, что ожидаемое количество конверсий для посетителя, который последний раз зашёл на сайт год назад, и c тех пор не появлялся, будет близко к нулю. В то же время посетитель, который заходил на сайт вчера, имеет гораздо больше шансов на появление новых конверсий, чем предыдущий. Поэтому время с момента последней активности time_since_last обязательно должно быть включено в модель.
Но в истории действий посетителей, из которой формируются данные для обучения, нет понятия
“текущее время”. В принципе любой момент после первого появления посетителя на сайте может быть выбран, как текущий.
Тогда то, что было то этого, принимается за историю, а на основе того, что было после, рассчитывается
целевая переменная, т.е. количество конверсий или сумма заказов.
$t_0$ – время первого появления посетителя на сайте; $t_{end}$ –
максимальное время в данных; $t_1,\dots,t_9$ – случайные моменты времени, используемые для обучения.
Итак, для каждого посетителя мы будем случайным образом выбирать “текущий” момент времени, причём для одного и того же посетителя может быть выбрано несколько разных моментов, относящихся к разным периодам его жизни. Заодно мы таким образом проводим data augmentation: из одного физического посетителя генерируем несколько “виртуальных”. От каждого текущего момента отсчитывается 60 дней в будущее и берётся суммарное количество конверсий за этот период в качестве целевой переменной.
У посетителей, которые очень давно не были на сайте, количество ожидаемых будущих конверсий стремится к нулю (они скорее всего уже никогда не вернутся). Поэтому имеет смысл ограничить максимальный период “бездействия” сроком, например, в 180 дней. Т.е. будем включать в обучающую и тестовую выборки только таких посетителей, у которых последнее событие было не позже 180 дней от текущего момента времени. У остальных посетителей ожидаемое количество конверсий можно считать нулевым.
Результаты, shop.ml
На тестовой выборке получен Concordance Index ~94%, это очень хороший показатель. В качестве тестовой выборки использовались данные за последние два месяца, которые модель не видела при обучении и настройке (из двенадцати имеющихся месяцев) – всё, как в реальной жизни.
Чтобы эксперимент был честным, из данных были удалены сессии посетителей, которые посещали внутренние домены, недоступные из внешнего мира (т.е. сессии персонала магазина и разработчиков). Если не удалять эти данные, то модель легко обучается распознавать такие нетипичные сессии, и Concordance Index вырастает до 95-96%.
Посмотрим на влияние признаков (методика интерпретации диаграмм влияния описана в предыдущей статье):
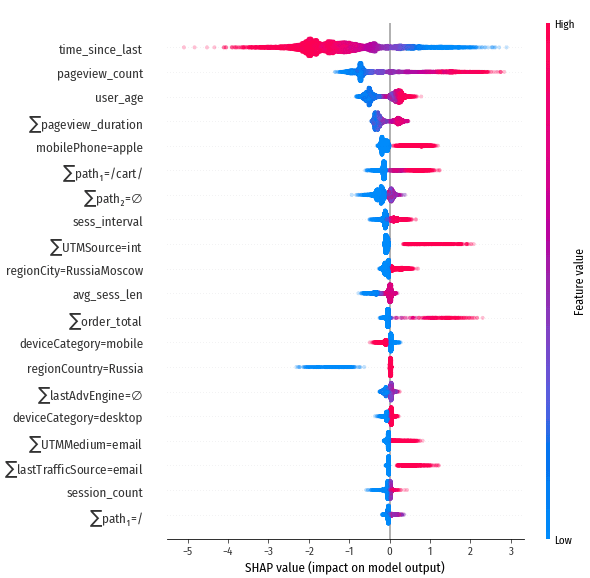
Признаки с наибольшим абсолютным влиянием, сайт shop.ml
Решающую роль играет признак time_since_last, не зря мы включили его! Также выраженное положительное влияние у pageview_count и $\sum$order_total (суммарная стоимость всех заказов посетителя). Физический смысл SHAP values: изменение SHAP value на одну единицу изменяет ожидаемое количество конверсий в два раза. Т.е. например value=2 даёт 4x прирост количества конверсий относительно среднего по сайту (в среднем на одного посетителя shop.ml приходится 0.00086 будущих конверсий)
Посмотрим
на детальные диаграммы:
С течением времени SHAP value изменяется от +2.5 до -2.5, т.е. ожидаемое
количество конверсий падает в ~32 раза за 180 дней.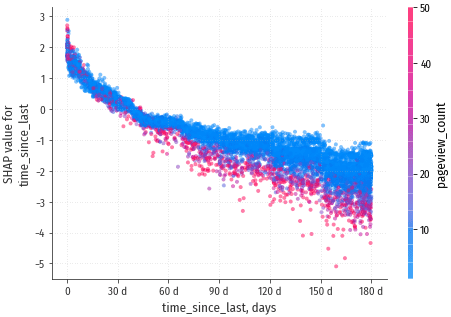
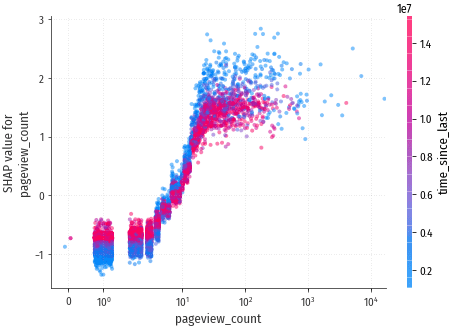
Количество будущих конверсий начинает расти после просмотра 4-x страниц. Просмотр более 30 страниц вызывает рост кол-ва конверсий примерно в 4 раза.
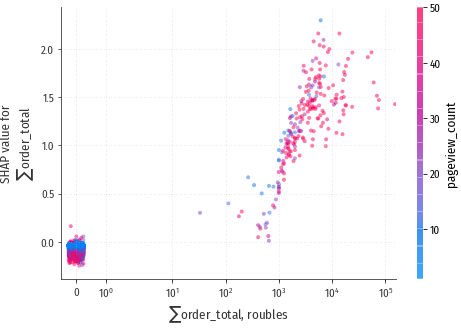
Клиенты, которые заказывали много, продолжат делать заказы – видна выраженная зависимость ожидаемого кол-ва конверсий от суммы заказов.
В этой модели нам интересны не столько зависимости от признаков, сколько результаты прогноза. Чтобы лучше понять, что предсказывает модель, разобьём тестовую выборку на несколько групп, в соответствии со значением целевой переменной:
- 0 конверсий
- 1 конверсия
- 2 конверсии
- 3 конверсии
- от 4 до 5 конверсий
- более 5 конверсий
и будем смотреть, насколько точным получается прогноз для каждой группы.
Количество примеров в каждой из групп. Группа с нулевой конверсией содержит
более чем в 1000 раз больше примеров, чем остальные группы (обратите внимание на логарифмическую шкалу).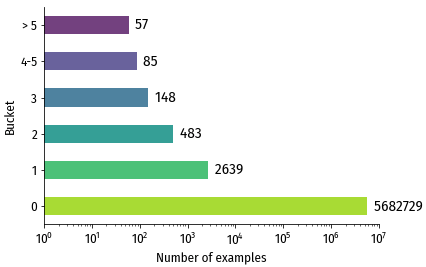
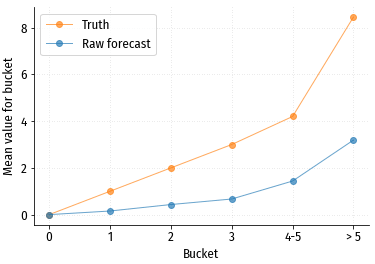
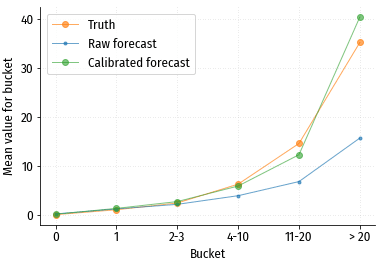
Сравнение прогнозных и истинных средних значений в каждой группе.
По графику видно, что чуда не произошло: прогноз и истина не совпадают. Форма кривой прогнозных значений в принципе близка к форме кривой истинных значений, и также монотонно растёт. Т.е. такие прогнозные значения вполне можно использовать, как абстрактную оценку потенциала посетителя, и для сравнения посетителей друг с другом. Но для каких либо абсолютных оценок (например, сколько конверсий ожидается в конкретном сегменте посетителей?) такой прогноз не годится. Впрочем, ситуация легко поправима.
Калибровка прогноза
Наша модель предполагает, что значения целевой переменной распределены более-менее в соответствии с распределением Пуассона. Посмотрим, сколько значений в каждой группе было бы, если бы значения были действительно распределены таким образом, т.е. посчитаем вероятное кол-во примеров в каждой группе для распределения Пуассона с $\lambda=0.00086$ (среднее кол-во конверсий на посетителя):
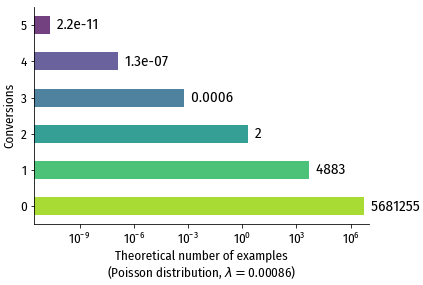
Видно, что наличие 3-х и более конверсий – крайне маловероятно,
ожидаемое количество примеров в этих группах приближается к нулю. То есть
распределение Пуассона не очень хорошо описывает то, что происходит в реальной жизни.
Количество примеров с нулевой конверсией в наших данных настолько велико, что они
“перетягивают одеяло на себя”, модель считает отличное от нуля значение маловероятным,
и занижает прогноз для примеров, в которых ожидается ненулевое количество конверсий. Это видно
и на распределении прогнозных значений:
Сравнение распределений истинных и прогнозных значений. Видно, что прогнозные значения “прижаты” влево,
в область меньших величин.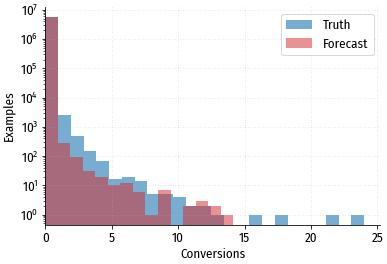
В принципе можно было бы подобрать вместо распределения Пуассона другое, с более тяжелым “хвостом” справа (fat-tailed), например что нибудь из семейства распределений Парето. Мы пойдем более простым путём, и просто применим к прогнозам преобразование, которое приведёт их к правильному масштабу. Поиск и использование такого преобразования называется калибровкой модели.
Существуют разнообразные методики калибровки различной степени сложности, включая даже обучение отдельной модели, которая будет получать на вход прогнозы исходной модели и выдавать откалиброванный прогноз. Но мы не будем мудрить, у нас уже почти правильный прогноз, достаточно просто домножить его на константу и немного скорректировать форму “загиба” в конце кривой: $$y^* = \hat{y}^{\beta}k $$ где $\hat{y}$ – исходный прогноз; $y^*$ – калиброванный прогноз; $k, \beta$ – коэффициенты, минимизирующие ошибку прогноза, и подбираемые с помощью кросс-валидации.
После калибровки получается такой график:
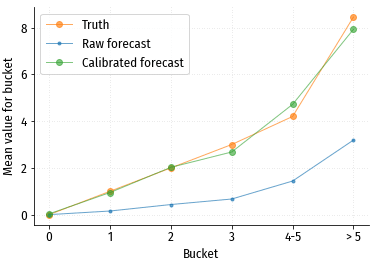
Стало намного лучше! Такой прогноз уже вполне можно использовать для абсолютной оценки потенциала сегмента аудитории.
Индивидуальные прогнозы
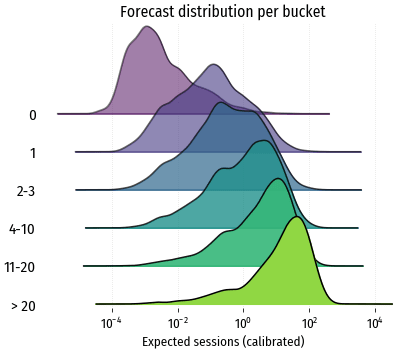
Мы рассматривали средний прогноз для аудиторного сегмента, а что с прогнозами на уровне отдельных посетителей, насколько они хороши? Чтобы получить представление об этом, построим распределения прогнозных значений отдельно для каждой группы:
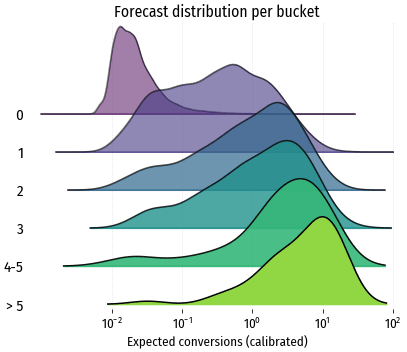
В идеале все распределения должны быть узкими, вытянутыми по вертикали вдоль истинного значения. В реальности распределения достаточно размыты: для истинного значения 1 конверсия 90% прогнозов находится в интервале от 0.02 до 3.9; для значения 3 конверсии – в интервале от 0.4 до 8.6.
Таким образом, совсем точного персонального прогноза не получается: для этого потребовалась бы настоящая машина времени, которая заглянет в будущее, и скажет, какое решение, покупать или не покупать, примет посетитель. Но если делать групповой прогноз, то ошибки “в плюс” и “в минус” нейтрализуют друг друга, и точность значительно вырастает.
Прогноз суммы заказов, shop.ml
Используется точно такая же модель, как и для прогноза конверсий,
заменяется только целевая переменная. По своим характеристикам модель
получается очень похожей на предыдущую, остановимся только на отличиях:
Сравнение распределений истинных и прогнозных значений. Распределение истинных
значений принципиально отличается от прогнозных.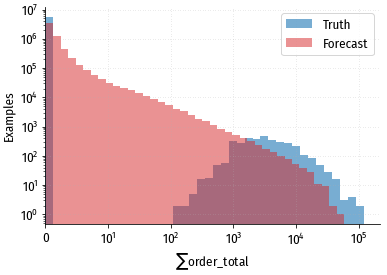
Тем не менее, на групповом уровне после калибровки получается очень приличный прогноз:
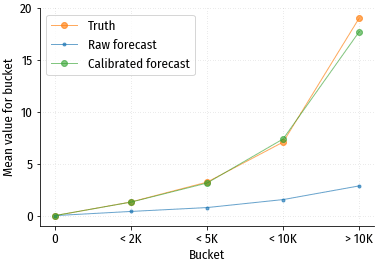
Прогноз с разбивкой на группы: 0 (нет заказов), 0-2000 руб., 2000-5000 руб., 5000-10000 руб., > 10000 руб.
Использование распределения Твиди, которое теоретически может быть мультимодальным, дало результат, практически не отличающийся от распределения Пуассона. Видимо, чтобы получить более правильные прогнозные значения, надо честно смоделировать процесс генерации данных, и делать два прогноза, первый – будут ли вообще заказы, и второй – сумма ожидаемых заказов.
Результаты для luxshop.ml
Тоже получилась очень похожая на предыдущую модель, с близким
Concordance Index и с аналогичным влиянием признаков на прогноз:
Признаки с наибольшим абсолютным влиянием, сайт luxshop.ml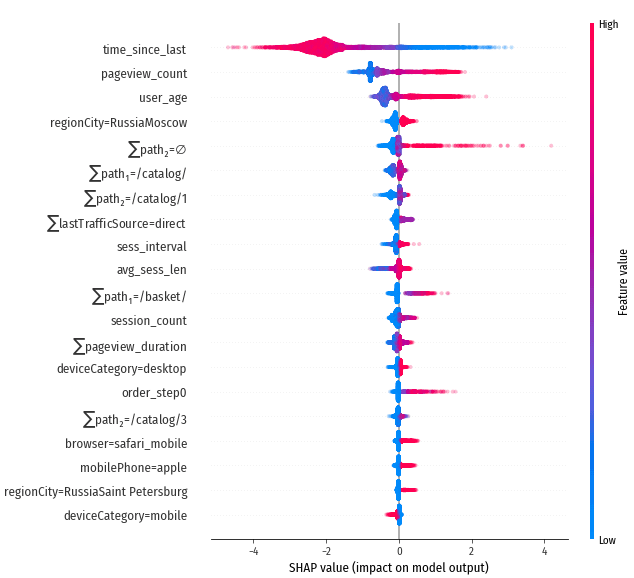
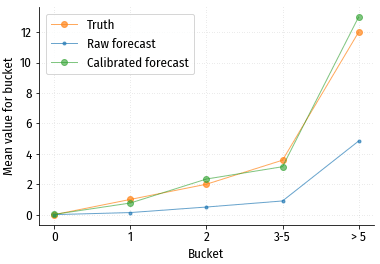
Ошибка предсказания после калибровки получилась немного больше, чем у shop.ml, возможно потому, что у luxshop.ml в целом меньше данных и меньше размеры групп, например в группе “2 конверсии” всего 116 посетителей, в отличие от 483 у shop.ml.
Результаты для courses.ml
На этом сайте нет целей типа “заказ”, поэтому будем предсказывать не количество конверсий, а количество сессий за следующие 60 дней. Concordance Index этой модели 90%, несколько хуже, чем у магазинов.
Признаки с наибольшим абсолютным влиянием, сайт courses.ml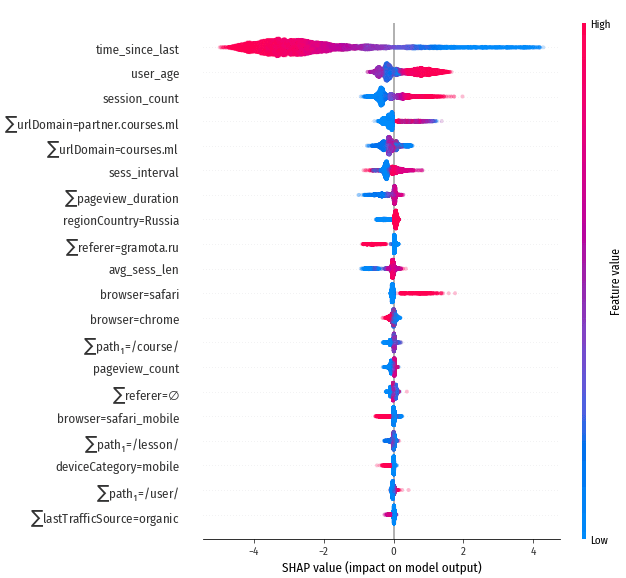
Дисперсия прогнозов внутри каждой группы выше, чем при прогнозе конверсий. Например, для группы “1 сессия” 90% прогнозов лежит в диапазоне [0.0015, 5.7], в то время как для shop.ml аналогичный диапазон “1 конверсия” более узкий: [0.02, 3.9]. То есть предсказывать количество будущих сессий сложнее, чем количество конверсий.
Scorecards
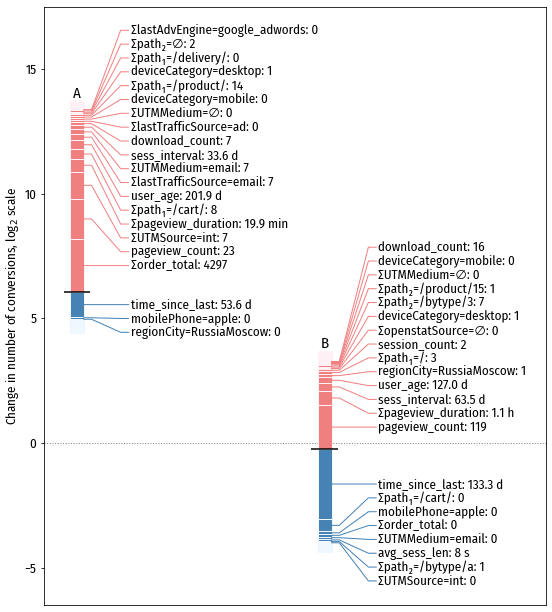
Образцы scorecards для прогноза количества конверсий на сайте shop.ml. Одному делению шкалы соответствует изменение количества конверсий в 2 раза.
Одно из преимуществ применяемого нами подхода это то, что прогноз не является чёрным ящиком, или предсказанием, волшебным образом появившимся из недр модели. Ведь довольно трудно принимать бизнес-решения на основе непонятной AI магии. А вдруг модель ошибается? Вдруг на вход пришли такие данные, с которыми модель не обучена работать?
Но благодаря наличию SHAP values, работа модели становится абсолютно прозрачной. Достаточно просто посмотреть на scorecard, чтобы понять, почему для данного посетителя выдан такой прогноз, и соотнести решение, принятое моделью, с собственным опытом и здравым смыслом. Это не оставляет места никакой магии: есть обоснование решений, можно или согласиться с ним, или не согласиться и перестать использовать модель (или отправить модель на переобучение).
Кстати, не до конца решенная проблема в машинном обучении – это проверка и тестирование всего конвейера подготовки данных для модели. В коде легко допустить ошибку, которая будет совершенно невидима извне, и единственное её проявление будет в ухудшении качества работы модели. Но заметить это ухудшение очень сложно, т.к. нет эталона качества. SHAP values помогают и здесь: за время подготовки моделей для этих статей я обнаружил с помощью SHAP-диаграмм несколько серьезных ошибок, которые в противном случае надолго (возможно навсегда) остались бы незамеченными.

Заключение
Мы убедились в том, что прогноз будущих конверсий и CLV для посетителей сайта вполне возможен и даёт пригодные для практического использования результаты даже на несложных моделях.
Конечно, это модели еще не пригодны для применения в production, есть ещё много вещей, которые можно сделать лучше. В частности, мы использовали весьма простое конструирование признаков: всего два уровня адресов страниц; игнорировали содержащиеся в URL параметры, которые могут нести ценную информацию о действиях посетителя; никак не разделяли действия, которые были совершены недавно и действия, которые были в далёком прошлом; использовали из данных о заказах только сумму заказа; не обращали внимания на последовательность действий (брали только суммарное их количество).
Также использовался ограниченный набор входных данных: у нас не было ни соцдема, ни поисковых фраз, ни внутренней информации о посетителях, которая содержится в CRM магазина, ни информации о взаимодействии с сайтом на интерфейсном уровне, подобной той, которую собирает WebVisor. Если задействовать больше данных, то прогнозы, естественно, станут более точными.
Структура данных о действиях посетителей в принципе очень близка к структуре данных о действиях пользователей мобильных приложений, т.е. аналогичные модели можно использовать и для работы с CLV в монетизируемых приложениях и играх.
