В предыдущей статье мы рассмотрели самую простую модель оценки конверсионности посетителя по параметрам первого посещения. Благодаря использованию SHAP values можно интерпретировать модели любой сложности, поэтому усложним задачу, и оценим конверсионность посетителя, у которого есть история предыдущего взаимодействия с сайтом.
Наличие такой истории даст нам много новой и полезной информации о намерениях посетителя. Но для начала немного разберёмся с микроструктурой данных, в частности с понятиями “визит/сессия” и “переход”, которые в современной интернет-аналитике перемешаны друг с другом. Работа полученных моделей будет оцениваться на тех же сайтах , что и в предыдущей статье.
Что такое сессия?
Базовое понятие интернет-аналитики, вокруг которого выстраивается большинство показателей, которые мы видим в отчётах, это сессия (она же визит в русскоязычной интерпретации). Под сессией обычно подразумевается интервал времени, в котором не было более чем получасовых пауз в активности посетителя. То есть посетитель пришёл на сайт (сессия началась), что-то посмотрел, ушёл обедать, через час вернулся, и его послеобеденная активность на сайте засчитается уже в новую сессию. Хорошо ли это?
На самом деле этот получасовой тайм-аут имеет происхождение ещё из тех доисторических времён, когда пользователь натурально выходил в интернет с помощью модема, и по завершению сеанса работы (с поминутной оплатой) отключался. Естественно, никто в здравом уме не ушёл бы на обед с подключенным модемом и продолжающейся сессией. Получасовой тайм-аут вполне соотносился с реальностью и соответствовал общепринятой практике работы c интернетом.
Но в современном мире человек находится в онлайне всегда, и сайт может быть открыт во вкладке браузера днями, неделями и даже месяцами: пользователь просто будет переключаться на вкладку с сайтом в моменты, когда в этом возникает необходимость. Эти переключения никак не связаны с “сеансом работы в интернет”, и тайм-аут 30 минут в современных реалиях оказывается просто взятым с потолка. Поэтому лучше определить тайм-аут, исходя из реальной статистики поведения людей на сайтах.
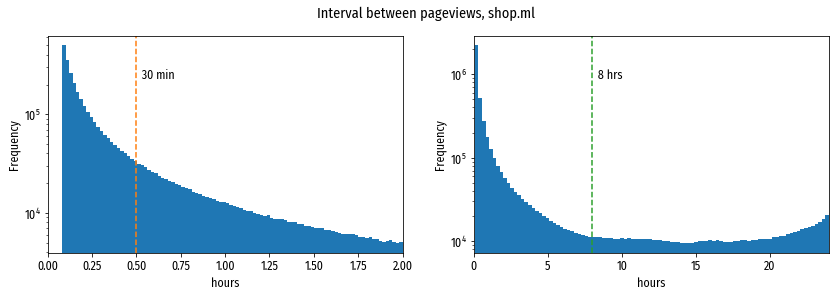
Распределение интервалов между просмотрами страниц каждым посетителем сайта shop.ml. Слева отображены интервалы от 5 минут до 2 часов, справа от 5 минут до 24 часов. Такое же распределение, с незначительными отличиями, наблюдается и на других сайтах.
На левой диаграмме видно, что точка “30 минут” не обладает никакими особенными свойствами: количество интервалов плавно падает с возрастанием размера интервала, и до, и после этой точки. На правой диаграмме более интересная картина: начиная примерно с 8 часов интервалы между просмотрами выходят на “равнину”, а ближе к 24 часам количество интервалов даже растёт. Рост объясняется суточной цикличностью, например человек посмотрел сайт перед уходом на работу, количество времени было ограничено, поэтому “досматривает” его на следующий день примерно в то же время. Но нас больше интересует момент выхода на минимальную вероятность интервала: разумно предположить, что 8 часов это и есть наиболее естественный тайм-аут между сессиями. Этот тайм-аут мы и будем использовать в дальнейшем во всех моделях.
Сессии или переходы?
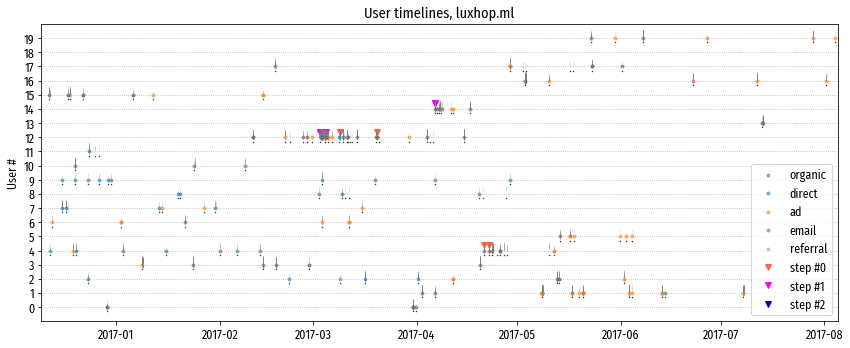
“Истории жизни” нескольких посетителей сайта. Цветными кружками обозначены переходы на сайт, цветными треугольниками – достижения целей, тонкими вертикальными штрихами – просмотры страниц, черными точками – моменты начала сессий.
На диаграмме видно, что обычно переход на сайт совпадает с началом сессии, но не всегда. Возможны сессии без переходов, например у пользователей #11 и #17 (вероятно, сайт висит во вкладке браузера и пользователь время от времени переключается на него), и наоборот, возможны переходы внутри сессий. На диаграмме переходы внутри сессий не очень хорошо различимы (несколько полупрозрачных кружков сливаются в один более насыщенный), поэтому рассмотрим подробную историю переходов одного из посетителей, например #15:
| Дата и время | Тип перехода | Номер сессии |
|---|---|---|
| 2016-12-12 00:03:59 | organic | 1 |
| 2016-12-17 15:18:20 | ad | 2 |
| 2016-12-17 15:19:46 | direct | 2 |
| 2016-12-18 00:25:05 | ad | 3 |
| 2016-12-22 00:19:23 | direct | 4 |
| 2016-12-22 00:20:25 | ad | 4 |
| 2016-12-22 00:24:11 | ad | 4 |
| 2017-01-06 00:20:07 | ad | 5 |
| 2017-01-06 00:21:51 | direct | 5 |
| 2017-02-13 19:13:00 | ad | 6 |
| 2017-02-13 19:13:27 | ad | 6 |
Видно, что в течение многих сессий совершается два или три перехода. В среднем по всем посетителям количество переходов на 15-30% превышает количество визитов.
Как с этим поступают современные системы интернет аналитики? Очень просто: каждый новый переход на сайт считается началом нового визита. Фактически переходы приравниваются к визитам, что приводит к тому, что у посетителей, совершающих много переходов, визиты нарезаются в мелкую лапшу. Для систем интернет-аналитики это нормальный компромиссный подход, в противном случае пришлось бы ввести дополнительную сущность “переход” и все отчёты сильно бы усложнились.
Но мы при построении моделей не станем упрощать действительность и честно учтём визиты и переходы, как отдельные сущности. Границы визитов будут определяться только таймаутом 8 часов, и ничем более.
Конструируем признаки
Перейдем к собственно моделированию. Мы рассматриваем посетителей, которые уже сделали хотя бы один переход на сайт, то есть у них есть история. История содержит данные о сессиях, переходах, просмотрах страниц, кликах на ведущие вовне ссылки, загрузках файлов и т.п. Как и в прошлой модели, будем рассматривать посетителя в момент, когда он совершает новый переход на сайт (только это будет уже не первый переход), и предсказывать, произойдет ли конверсия до следующего перехода или до завершения сессии.
К признакам, которые уже были в предыдущей модели, добавляются новые признаки, сконструированные по историческим данным. Пример нескольких таких признаков:
- time_since_prev_landing – интервал времени с момента предыдущего перехода на сайт.
- time_since_sess_start – интервал времени от начала сессии до текущего перехода. Для переходов, совпавших с началом сессии, равен нулю.
- time_since_prev_sess – интервал времени от последнего события в предыдущей сессии до текущего перехода
- landing_num – порядковый номер текущего перехода во всей истории переходов
- sess_interval – средний интервал времени между сессиями посетителя, по данным предыдущих сессий.
- avg_sess_len – средняя продолжительность сессии посетителя, по данным предыдущих сессий.
- $\sum$order_stepn – количество достижений цели, являющейся n-ным шагом в конверсионной воронке, т.е. одним из этапов совершения заказа, за всю историю до текущего момента.
- user_age – “возраст” посетителя, т.е. промежуток времени от момента, когда посетитель впервые зашёл на сайт, до текущего перехода. нет смысла засчитывать это время, как активное).
- $\sum$path1=X, $\sum$path2=X – суммарное количество просмотров страниц в истории, соответствующих
пути X (берётся первый уровень пути для path1, первый и второй уровни для path2).
Это запись в нотации Айверсона
$\sum[path_i=X]$, у которой опущены для краткости квадратные скобки.
В обобщённом виде, без указания конкретного пути, эти признаки записываются как
path1_history и path2_history.
Все ли признаки одинаково полезны?
На основе истории посетителя можно сконструировать в общем то неограниченное количество признаков, лимитом здесь является только фантазия автора модели. Возникает логичный вопрос – в какой момент надо остановиться? Проблема в том, что несмотря на объем данных (миллионы посетителей), в них не так много положительных примеров совершившихся конверсий (всего несколько тысяч). В то же время количество признаков в моделях, учитывая что у нас в основном категориальные признаки, которые переводятся в числовые через one-hot encoding, тоже легко переваливает за тысячу и приближается к количеству позитивных примеров. Это означает, что наши модели потенциально подвержены переобучению.
Если подать на вход модели просто шум вместо реальных признаков, всё равно в нём найдутся случайные корреляции с целевой переменной (конверсией), модель сделает вид, что обучилась, и даже будет показывать степень влияния “признаков” на результат. Но это влияние будет миражом, фейковой новостью, и только введёт в заблуждение пользователя модели. Любой из сконструированных нами признаков в принципе может оказаться таким шумом, и ухудшить способности модели к предсказанию на новых данных. Как же определить, в каких признаках содержится полезный сигнал, а в каких только шум?
Некоторые виды моделей, например деревья решений, способны выдавать показатели “важности” признаков (feature importance), и обычно полезные признаки отбирают именно по этим показателям. Но эта “важность” точно так же переобучается, как и сама модель: в конечном итоге важность это показатель того, сколько корреляций с целевой переменной обнаружила модель в признаке. Это корреляции могут оказаться просто случайными.
Мы пойдём более честным, хотя и вычислительно затратным путём, и будем использовать метод, называемый Sequential Feature Selection. Суть метода простая: в начале есть набор из всех имеющихся признаков. На каждом шаге мы убираем по очереди один из признаков, заново обучаем модель, и смотрим, как изменится качество её работы на тестовой выборке. Если признак был бесполезен и содержал шум, качество повысится. Если мы наоборот убрали полезный признак, качество упадёт. По итогам исключается признак, без которого модель работает лучше всего, и цикл начинается снова, уже с уменьшенным набором признаков. Так признаки исключаются до тех пор, пока не останется ни одного. Признаки, исключенные последними – самые важные; признаки, исключенные первыми – самые бесполезные, или даже вредные.
Вычислительная сложность такого метода $q \times n^2/2$ циклов обучение-валидация, где $n$ это количество признаков, $q$ это количество разбиений в кросс-валидации. Это довольно много, поэтому получить разумное время вычислений удалось только при использовании нескольких GPU.
Ниже представлены результаты для одного сайта (часть признаков скрыта):
Результат работы полного цикла Sequential feature selection.
В основном доминируют признаки, относящиеся к адресам просмотренных страниц,
на их фоне роль других признаков слабо различима.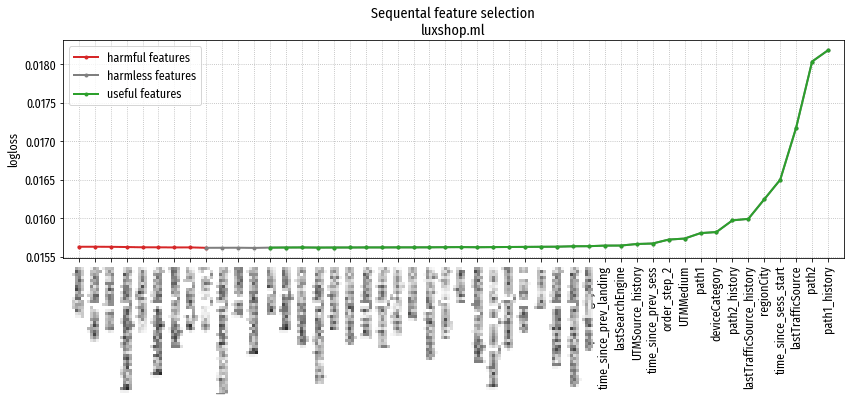
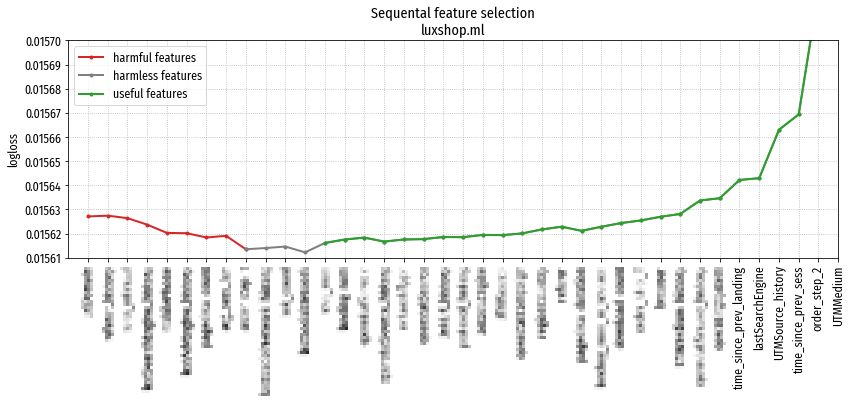
Отдельно “маловажные” признаки. Видно, как ошибка модели (logloss) сначала падает, потом начинает расти.
Признаки, удаление которых привело к улучшению работы модели (т.е. вредные), показаны красным; признаки, удаление которых привело к улучшению (полезные) показаны зелёным; нейтральные – серым.
По результатам feature selection для каждого сайта были отброшены признаки из красной зоны и часть признаков из серой.
Модель для luxshop.ml, результаты
Проверка обученной модели на тестовой выборке дала AUC около 86%, что очень неплохо для предсказаний действий посетителей, ведущих себя в общем то случайным образом. AUC заметно вырос по сравнению с предыдущей моделью по первому переходу на сайт (было ~75%), потому что появилось много дополнительной информации из истории посетителя.
В предыдущих моделях все используемые признаки были категорийными, и мы измеряли только влияние наличия признака, т.е. да/нет. В новых моделях многие признаки это числовые значения, например время с момента последнего перехода может быть любым числом от нуля до $\approx3.2 \times 10^7$ (количество секунд в году), поэтому поход к интерпретации влияния признаков будет другим.
Для начала визуализируем признаки, обладающие наибольшим абсолютным влиянием на модель:
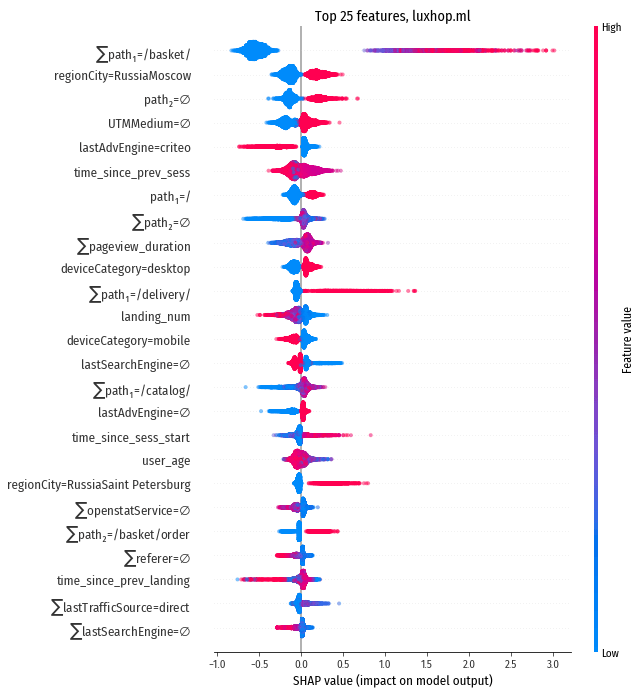
Это довольно сложная визуализация, требующая пояснений. Цвет объекта на диаграмме соответствует числовому значению признака. Минимальным значениям (в нашем случае это обычно ноль) соответствуют голубые цвета, максимальным значениям – красные, промежуточным значениям – оттенки синего, фиолетового и пурпурного. Диапазон от минимальных до максимальных значений индивидуален для каждого признака, например у бинарных признаков (таких как regionCity=RussiaMoscow) всего два значения, 0 и 1, и, соответственно, всего два цвета, красный и голубой.
Значение некоторых признаков равно ∅. Этим символом обозначается отсутствие
логического значения, например lastSearchEngine=∅, если переход совершался не из поисковой
машины, или path2=∅, если в URL перехода был только первый уровень,
например / или /catalog. Можно интерпретировать символ ∅, как “дырка от бублика”.
Каждый признак представлен набором точек: одна точка это один пример из тестовой выборки. Точек много, поэтому они сливаются в вытянутые по горизонтали облака. Координата точки по оси X соответствует степени влияния признака на результат. Вдоль диаграммы проходит вертикальная нулевая ось (серая линия), чем точка правее от этой оси, тем больше признак действует “в плюс”, чем левее, тем больше “в минус”. Размер этого влияния есть на шкале внизу диаграммы.
Чтобы облако точек для каждого признака не превратилось в горизонтальную линию, точки случайным образом разбросаны немного вверх и вниз от горизонтальной оси, соответствующей признаку. Чем больше точек уложено на отрезке оси, тем толще получается в этом месте облако после “разброса”. Например, если облако толще всего в околонулевых координатах по оси X, это означает, что для большинства примеров этот признак оказывает околонулевое воздействие на результат.
Чтобы стало понятнее, рассмотрим несколько топовых признаков по отдельности.
$\sum$path1=/basket/

Количество просмотров страниц в истории, URL которых начинался с /basket/.
Нулевые значения (голубое облако слева) оказывают отрицательное воздействие,
положительные (вытянутая красно-фиолетовая линия справа) – сильно положительное.
Степень положительного воздействия значительно отличается от примера к примеру
(большая дисперсия, вытянутая линия вместо облака). Эти же значения
можно отобразить на развёрнутой диаграмме:
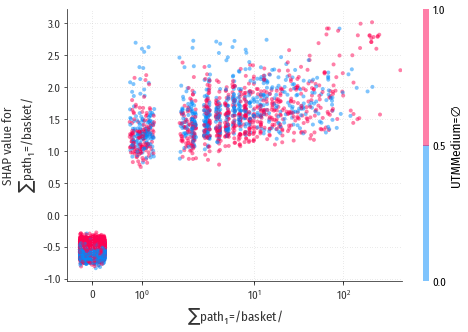
Эта диаграмма тоже требует пояснений. По оси X – значения нашего признака, в логарифмической шкале (от 0 до примерно 300). По оси Y – соответствующее воздействие на результат модели. Каждая точка это один пример из тестовой выборки. Значения немного “разбросаны” по оси X для лучшей визуализации, в противном случае например все значения, где X=0, выстроились бы в узкую вертикальную полоску, на которой сложно было бы разглядеть детали. Чем ближе значение к нулю, тем больше “разброс”.
Окраска точек отличается от окраски на мини-графике. Цвет каждой точки соответствует значению второго признака, в данном случае второй признак это UTMMedium=∅. Символ ∅, напомню, обозначает “пустоту”, т.е. если в URL перехода на сайт не было метки UTMMedium, значение признака UTMMedium=∅ равно единице, а если метка была, значение равно нулю. Но какое отношение UTMMedium имеет к признаку $\sum$path1=/basket/, зачем нам вообще второй признак?
Дело в том, что мы используем достаточно сложные модели, в которых большую роль играет взаимодействие признаков (feature interaction). Другими словами, влияние, которое оказывает на результат работы модели один признак, может зависеть не только от значения самого этого признака, но и от значений других признаков, взаимодействующих с первым. Визуализировать такое множественное взаимодействие непросто, поэтому применяется упрощённый подход: берётся единственный признак, который более всего взаимодействует с основным, и его значения используются, как палитра для раскраски точек. Соответствие цветов значениям вторичного признака отображается на вертикальной цветной полоске справа. В данном случае у нас бинарный признак, 0 или 1, поэтому на полоске всего два цвета, нулю соответствует голубой, а единице – красный.
Итак, что же мы видим на подробной диаграмме?
Если в истории посетителя не было ни одного захода на страницы, связанные с корзиной, т.е. значение признака $\sum$path1=/basket/ равно нулю, вероятность конверсии понижается примерно на 0.5 единиц. При этом, если в URL перехода на сайт нет метки UTMMedium, негативное влияние нулевого значения основного признака ослабляется: мы видим, что верх левого “столбика” на графике окрашен в красный цвет, а низ – в синий. Красный соответствует единичному значению вторичного признака, т.е. “метки нет”, а синий - наоборот, “метка есть”.
Если в истории был хотя бы один заход на страницу, относящуюся к корзине, вероятность конверсии сразу резко возрастает (для всех значений X > 0 вероятность повышается на 1-2 единицы). При этом значение вторичного признака уже не играет роли: красные и синие точки в “ненулевой” части графика перемешаны более-менее равномерно.
При повышении значения признака, положительное влияние растёт, т.е. чем чаще посетитель заходил в корзину, тем выше вероятность конверсии; при более чем 100 заходах положительное влияние может достигать трёх единиц.
Вот такое длинное описание потребовалось, чтобы расшифровать такую маленькую диаграмму 😌 Но мы теперь умеем интерпретировать такие диаграммы, и следующие описания будут короче.
regionCity=RussiaMoscow

Это бинарный признак, интерпретация очень простая: положительные значения
(посетитель из Москвы, красное облако справа) повышают конверсию, отрицательные (не из Москвы, голубое облако слева)
– понижают.
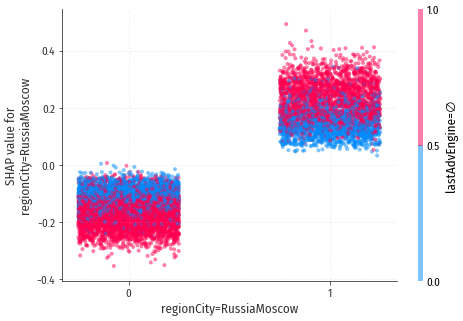
Заметно любопытное взаимодействие: если посетитель перешёл из поисковика (нулевое значение lastAdvEngine=∅, голубая окраска точек), влияние Москвы, как отрицательное, так и положительное, снижается.
time_since_prev_sess

По мини-графику сложно сказать что-то конкретное, кроме того, что в большинстве случаев
воздействие на конверсию околонулевое или слабо отрицательное (по положению утолщений).
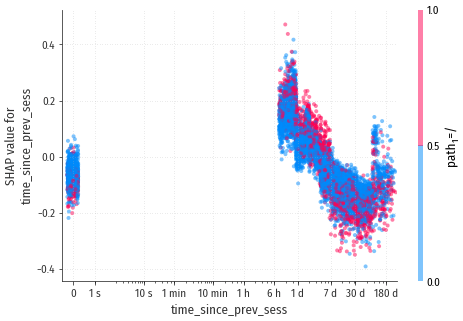
Виден большой разрыв в значениях, вызванный 8-часовым тайм-аутом сессии. Если переход происходит в рамках первой сессии, время от предыдущей сессии принимается равным нулю, в противном случае время от конца предыдущей сессии будет как минимум 8 часов.
Переход в первой сессии несколько снижает вероятность конверсии. Для переходов, совершённых в следующих сессиях, зависимость очень любопытна: есть “хорошее” время, примерно в течение недели после сессии, и “плохое”, от недели до двух месяцев. По видимому, в течение первой недели посетитель ещё “горячий”, с твёрдым намерением сделать покупку, а потом “остывает” и заходит на сайт просто посмотреть на товары, не собираясь их приобретать, или просто помимо своей воли перекидывается на сайт рекламными системами.
Прослеживается также интересное взаимодействие со вторым признаком.
$\sum$path2=∅
Это значение признака интерпретируется, как
количество раз, когда посетитель заходил на “топовые” страницы
сайта, не опускаясь вглубь, на второй уровень.

По мини-графику можно предположить, что большие значения признака имеют
в среднем нулевой эффект (красные точки сконцентрированы около нуля),
а околонулевые и близкие к ним значения могут проявлять
как положительное, так и отрицательное воздействие на конверсию. Также
в большинстве случаев воздействие признака на конверсию равно нулю или
чуть больше нуля (есть утолщение в районе нуля).
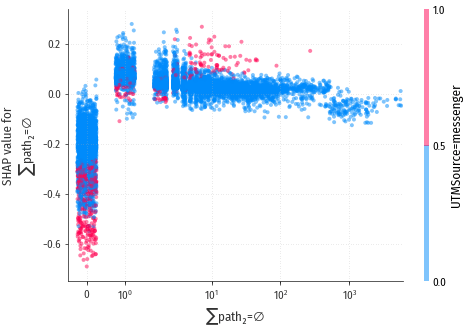
Развёрнутая диаграмма подтверждает наше предположение: Нулевое значение отрицательно действует на конверсию, единичное - максимально действует в “плюс”, и по мере увеличения значений признака воздействие уменьшается и становится снова отрицательным.
Также любопытно взаимодействие со вторым признаком: messenger, как UTM источник, сильно увеличивает негативное воздействие для нулевого значения основного признака.
Дальше будем рассматривать только развёрнутые диаграммы, т.к. дано уже достаточно примеров интерпретации мини-графиков.
$\sum$pageview_duration
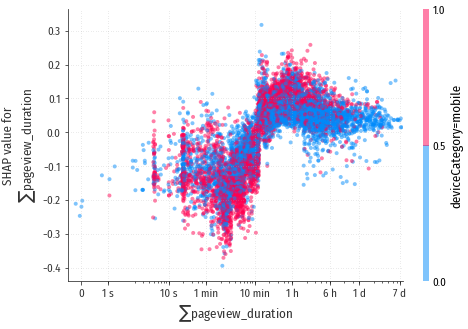
Хороший посетитель просматривал сайт достаточное время, но не слишком долго, оптимальное время от 10 минут до нескольких часов. Посетители, которые разглядывали сайт магазина более 6 часов, видимо используют его, просто как источник для вдохновения.
$\sum$path1=/delivery/
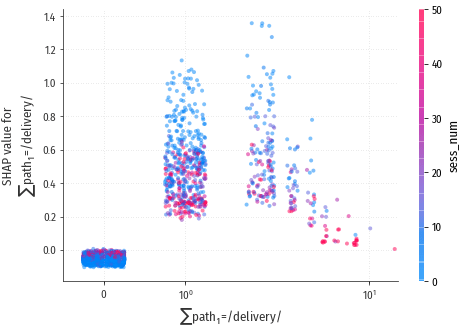
Идеальный посетитель интересуется доставкой дважды. Лучше, если это происходит в первой или второй сессии. Для посетителей, интересовавшихся доставкой более 7 раз, есть подозрение на проблемы с памятью: возможно, делать покупки они тоже забывают.
landing_num
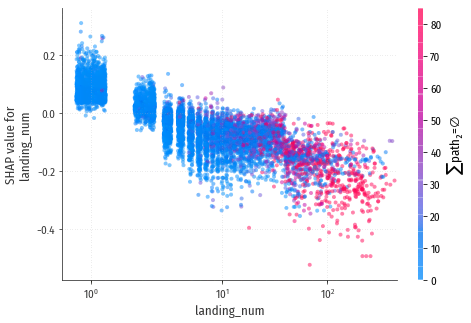
Принято считать, что чем чаще посетитель заходит в магазин, тем выше его лояльность, и тем лучший он покупатель. Но эта диаграмма показывает прямо обратное. Забегая вперёд, скажу, что похожая зависимость наблюдается и на других сайтах, т.е. это не случайное статистическое отклонение и не особенность этой модели. Причины такой зависимости будут более подробно разобраны позже, на примере сайта shop.ml.
time_since_sess_start
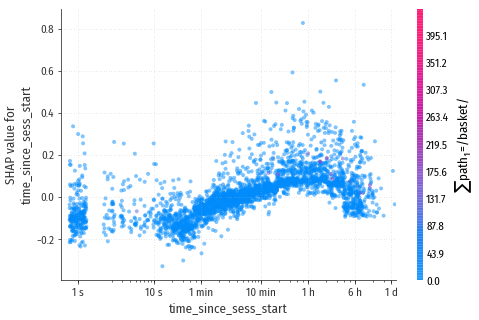
Модель показывает, что посетителю в идеале нужен примерно час от начала сессии, чтобы дозреть до решения о покупке.
user_age
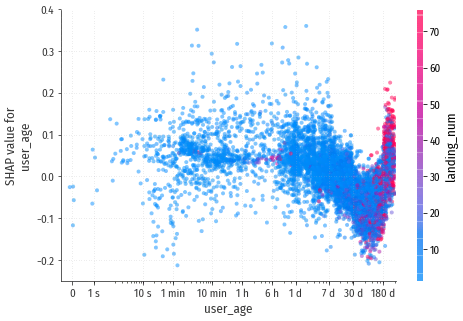
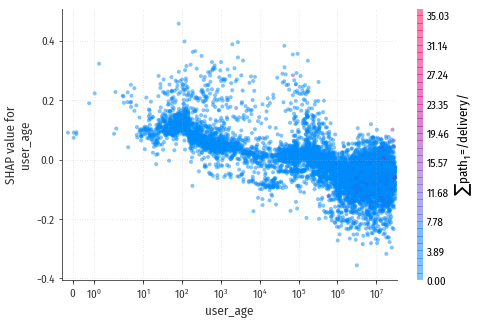
Как и в случае с landing_num, здесь не наблюдается однозначного повышения “качества” посетителей с увеличением времени их знакомства с магазином. Наоборот вероятность конверсии с возрастом падает, и только у “старой гвардии” возрастом более 120 дней опять начинает повышается. $$\DeclareMathOperator{\E}{E}$$
Ранжирование по среднему воздействию признака
До этого момента мы ранжировали признаки по силе их абсолютного воздействия,
то есть по $\sum_n|S_i|$, где $S_i$ это SHAP value i-го признака, $n$ –
количество примеров в тестовой выборке. Но можно отранжировать признаки
и по матожиданию $\E[S_i]$, как мы делали это в предыдущей статье,
и построить соответствующую диаграмму. Тогда в топ выйдут признаки, которые
в среднем влияют максимально положительно или максимально отрицательно:
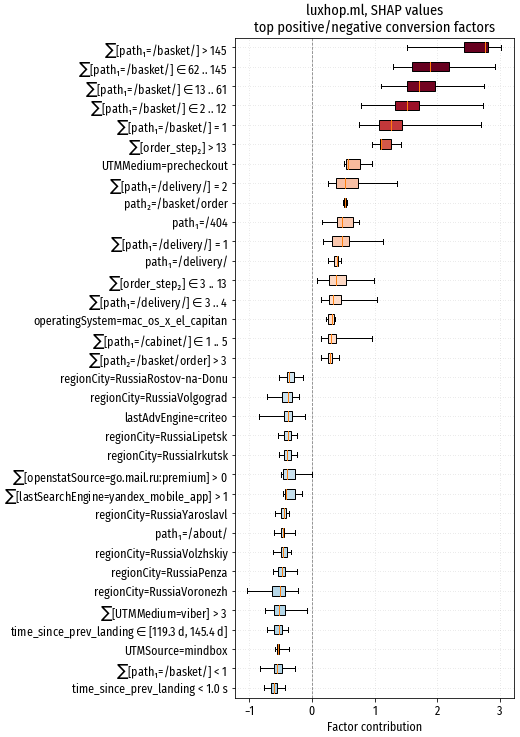
Всю верхушку положительного топа оккупировал признак $\sum$path1=/basket/, это
соответствует тому, что мы уже видели на диаграммах. Этот же признак, но
с нулевым значением – второй по негативному воздействию. Также в топе
неожиданно засветился признак path1=/404, скорее всего
соответствующий адресу страницы с ошибкой 404 Page not found.
Можно предположить, что такая ошибка выдавалась посетителям, у которых было
твёрдое намерение приобрести определённый товар, исчезнувший из ассортимента
магазина, и они всё равно делали заказ, приобретая замену.
User scorecards
Из рассмотренных примеров видно, что интерпретация воздействия признаков в продвинутой модели это не такая простая задача. Все диаграммы, которые мы построили, не охватывают думаю и нескольких процентов возможных кейсов по воздействию на конверсию и особенно по взаимодействию признаков друг с другом.
Поэтому для продвинутых моделей особенно хороши user scorecards, которые
позволяют без построения гипотез и абстрактных рассуждений просто взять и увидеть,
как конкретные значения признаков влияют на вероятность конверсии конкретного посетителя сайта.
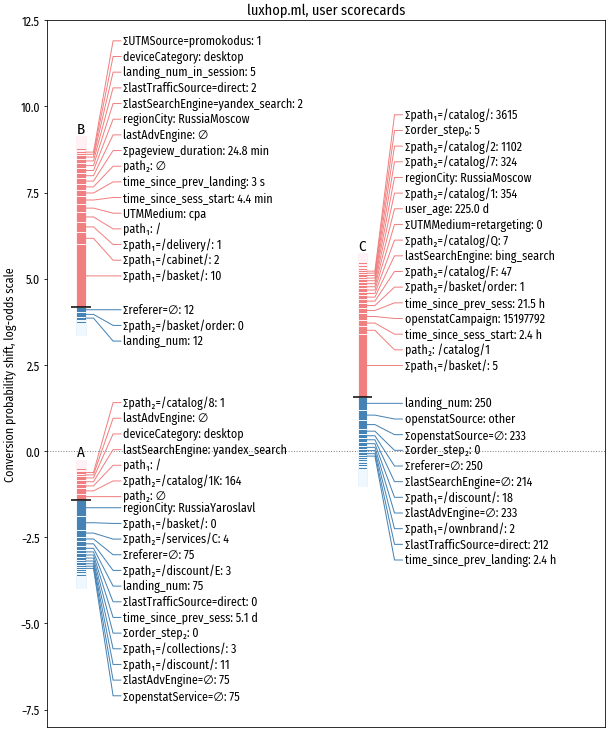
Напомню, черная горизонтальная черта это то, насколько вероятность конверсии данного посетителя отличается от средней по сайту (средней конверсии соответствует горизонтальная пунктирная линия, идущая из нулевой точки); красные столбцы над этой чертой – положительно влияющие признаки, размер каждого столбца равен силе влияния признака; синие столбцы под чертой – признаки с отрицательным влиянием.
Видно, что на конверсию каждого посетителя влияет большое количество признаков, их даже не получилось все детализировать на диаграмме (розовая и светло-голубая “шапки” сверху и снизу у каждого посетителя)
Результаты для shop.ml
Пр проверке модели на тестовой выборке получен AUC 84%. Посмотрим,
что есть интересного в признаках:
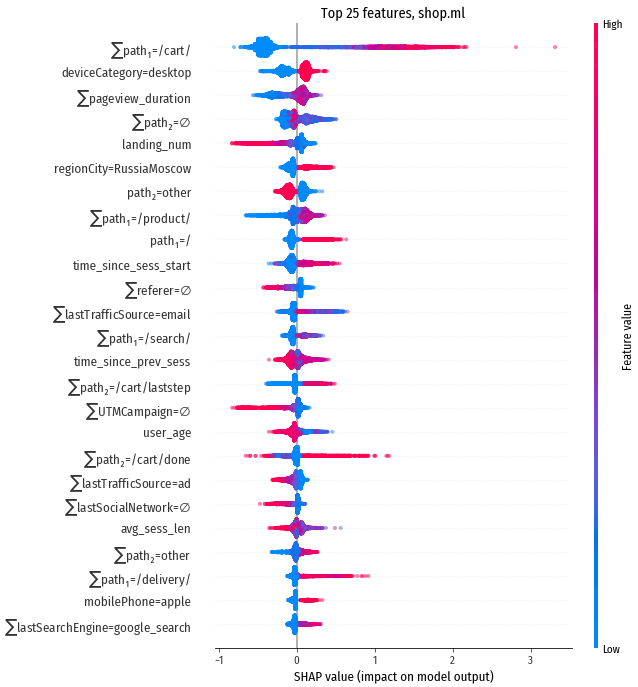
Прежде всего, отметим сильное влияние признака $\sum$path1=/cart/.
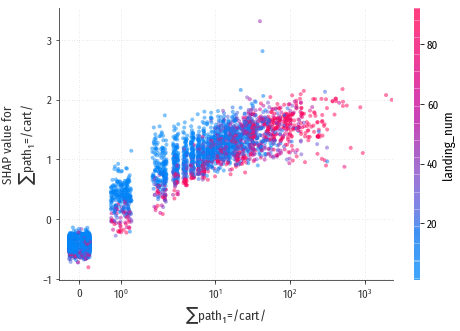
Уже единственный заход на страницу, связанную с корзиной, поднимает вероятность конверсии на полпункта, а три захода – на целый пункт (напомню, один пункт это изменение вероятности конверсии примерно в два раза). Ни один другой признак не влияет так сильно.
Cильное влияние и у признака $\sum$path2=/cart/done, также в топе есть $\sum$path2=/cart/laststep и $\sum$path1=/delivery/. Похоже, что работа с корзиной и доставкой является критически важным фактором в оценке посетителя.
Теперь посмотрим на признаки с выраженным отрицательным влиянием. Здесь нас
ждёт сюрприз.
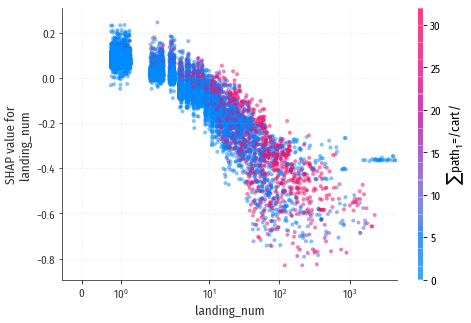
Признак с самым явно выраженным негативным влиянием это landing_num, порядковый номер захода на сайт.
Про росте значения признака конверсионность посетителя резко падает.
Казалось бы, должно быть наоборот: чем чаще человек пользуется сайтом,
тем более это лояльный покупатель?
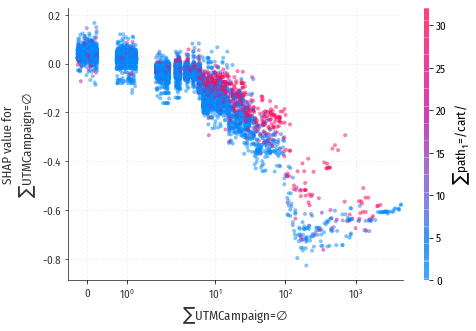
Схожим образом работает признак $\sum$UTMCampaign=∅ и близкие к нему
по смыслу признаки $\sum$referer=∅ и $\sum$lastSocialNetwork=∅.
При увеличении “возраста” посетителя его конверсионность тоже падает. Что же происходит с посетителями, у них постепенно вырабатывается отвращение к покупкам?
На самом деле нет. В данных сайта shop.ml заметно, что часть трафика приходит из довольно сомнительных источников. Представим источник, перекидывающий людей на сайт через popunder, clickunder или другим не слишком цивилизованным способом. У посетителей из таких источников будет много переходов, но так как они не собираются ничего покупать, они не будут работать с корзиной. Таких посетителей много: из всех посетителей, совершивших более 10 переходов на сайт shop.ml, меньше трети когда либо пользовались корзиной.
Но если посетитель совершает переходы и не работает с корзиной, значит это мусорный трафик, и модели надо научиться его распознавать? Да, и именно поэтому у признаков landing_num, user_age и признаков, связанными с пустыми UTMCampaign / referer / socialNetwork, наблюдается негативное влияние. Как только посетитель воспользуется корзиной, весь негатив от этих признаков сразу будет скомпенсирован сильным положительным влиянием признака $\sum$path1=/cart/. Ну а пока посетитель набирает переходы на сайт и не использует корзину, априори считаем его низкокачественным трафиком – вполне разумно.
В подтверждение этой версии, на диаграммах заметно взаимодействие признака $\sum$path1=/cart/ и генерирующих негатив признаков landing_num и $\sum$UTMCampaign=∅: работа с корзиной снижает степень негатива.
Взаимную компенсацию признаков видно и на scorecards:
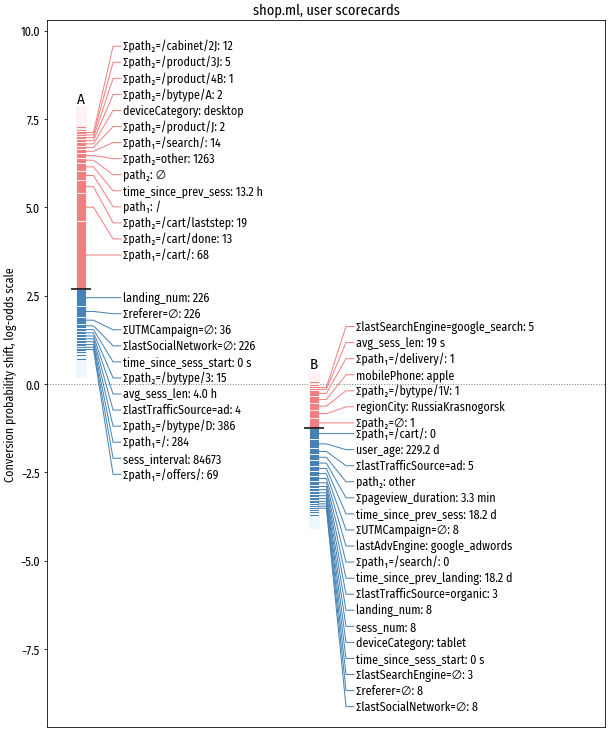
У посетителя A присутствует весь набор негативных признаков, тем не менее у него повышенная более чем на 2.5 пункта вероятность конверсии, потому что есть работа с корзиной. У посетителя B негативные признаки выражены не так явно, но прогноз конверсии в целом негативен, т.к. заходов в корзину не было.
Итак, фактически у нас получилась модель оценки качества трафика, использующая конверсионность, как метрику качества. Неплохо, не правда ли?
Результаты для courses.ml
Для этого сайта не существует цели “заказ”, поэтому сделаем синтетическую цель, соответствующую бизнес-задачам сайта. Сайт существует, чтобы обучать, поэтому конверсию будем засчитывать, если посетитель продержался на сайте ещё как минимум полчаса после перехода. Будем считать, что в эти полчаса он обучался, а не просто рассматривал картинки.
Суммарное влияние признаков:
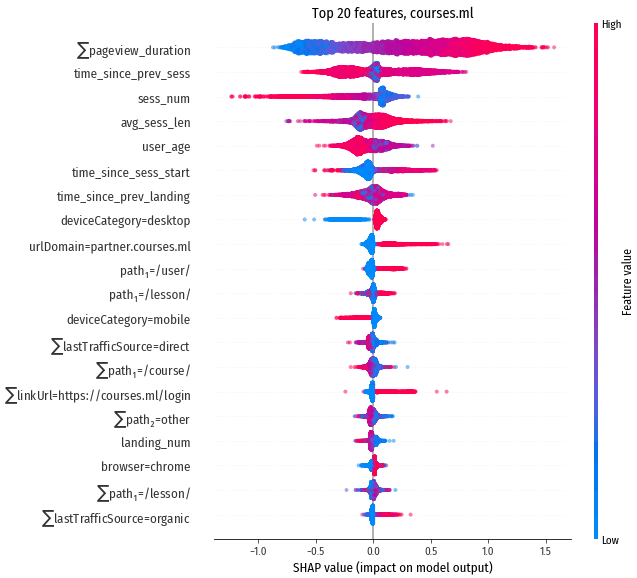
$\sum$pageview_duration
Более всего на результат влияет суммарное время просмотра страниц, т.е.
модель предполагает, что если посетитель уже потратил заметное количество времени на обучение,
он будет продолжать обучаться дальше.
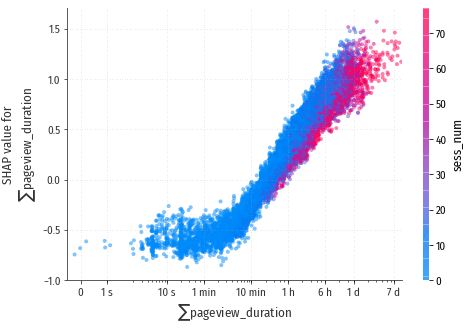
На детальной диаграмме зависимость выражена очень явно.
time_since_prev_sess
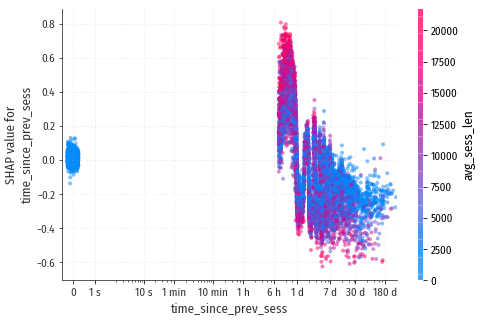
Прослеживается интересная форма зависимости, похожая на синусоиду. Рассмотрим
этот участок поближе, и в линейной шкале по оси X:
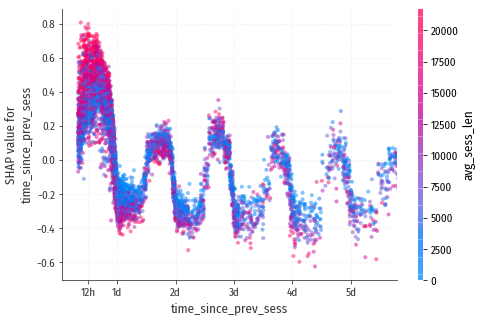
Действительно синусоида! Наша модель самостоятельно вывела такую сложную зависимость из входных данных, которые в общем то не предполагали никакой периодичности. Но какова причина появления этой синусоиды?
Люди серьезно занимающиеся самообучением, обычно проходят курс по вечерам после работы или после домашних дел. Или по утрам: конкретное время неважно, главное, что обучение происходит примерно в одно и то же время каждый день. В течение для есть довольно узкий интервал времени, в течение которого человек может сесть за обучение и по настоящему в него погрузиться. Если начать слишком рано, скорее всего найдутся другие занятия: работа, дом, дети, и т.п. Если начать слишком поздно, то просто пора будет спать. То есть, если с момента завершения предыдущей сессии обучения прошло менее 12 часов или более 22-24 часов, то новая сессия скорее всего получится неудачной или вовсе не начнётся. Примерно это мы и видим на диаграмме.
Синусоида с периодом в сутки образуется, потому что не принципиально, когда закончилась предыдущая сессия: вчера, позавчера, или три дня назад. Всё равно начало следующей сессии наиболее вероятно только в определённом интервале времени.
Почему максимум вероятности приходится не ровно на 24 часа с момента предыдущей сессии? Потому что время отсчитывается от конца предыдущей сессии, а не от начала. Сессии имеют достаточно большую длительность, она отображена справа на шкале взаимодействующего признака avg_sess_len. Размерность шкалы – секунды. Для понимания масштаба: 5 часов это 18000 секунд. Там же видно, что наибольший “размах” синусоиды наблюдается у посетителей с длинными сессиями. Если сеансы обучения короткие, то обучаться можно в принципе в любое время дня, и роль суточной периодичности снижается.
sess_num
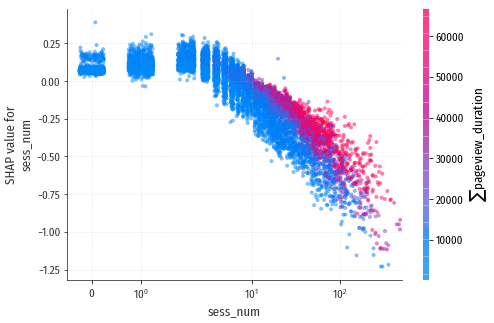
Онлайн обучение это занятие для достаточно терпеливых и упорных людей. Терпения и упорства не всем хватает надолго. После четвёртой сессии видно отрицательное влияние растущего номера сессии: известно, что онлайн курсы проходит до конца только небольшой процент начавших обучение. Кроме того, для усидчивых посетителей будет наблюдаться компенсационный эффект от растущего $\sum$pageview_duration (он виден и по взаимодействию признаков), а большие значения sess_num могут использоваться моделью для определения случайных переходов на сайт – аналогично механизму, описанному для сайта shop.ml.
time_since_sess_start
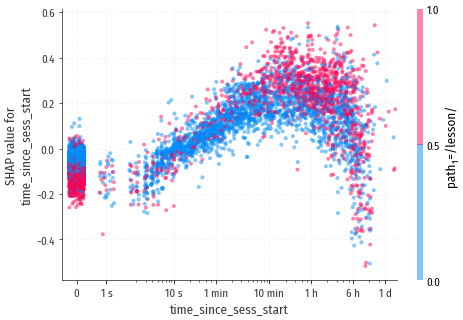
Для переходов, которые не совпали с началом сессии, модель вероятно рассуждает так: если посетитель просидел на сайте больше 10 минут, то скорее всего просидит и ещё полчаса. А вот если время с начала сессии приближается к 6 часам, то пора бы уже и закругляться!
time_since_prev_landing
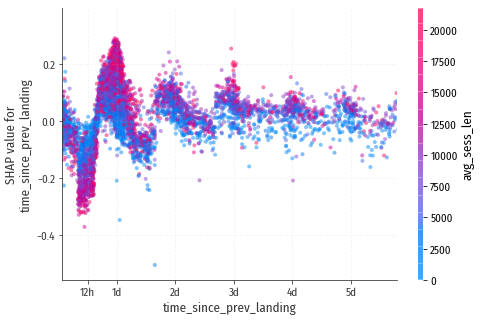
Синусоида, аналогичная time_since_prev_sess, но максимумы приходятся уже ровно на 24 часа, т.к. нет поправки на продолжительность сессии.
Дополнительные визуализации
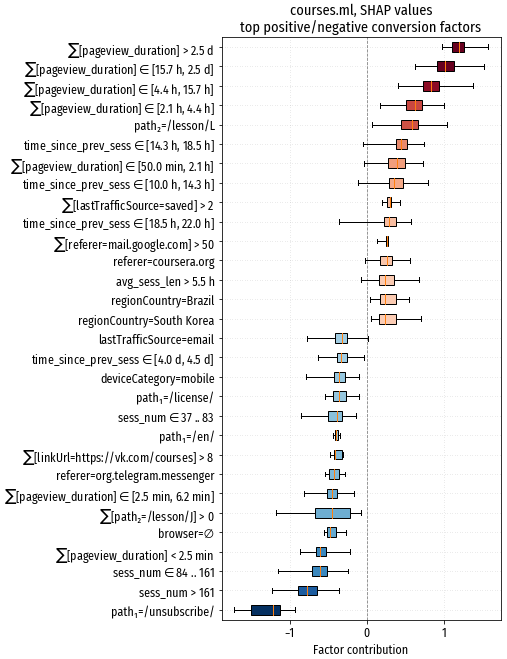
Эта визуализация представляет собой взгляд с альтернативной точки зрения, выявляющий несколько другие признаки. На что можно обратить внимание:
- path1=/unsubscribe/ резко понижает вероятность продолжения сессии. Неудивительно.
- $\sum$path2=/lesson/J – по видимому очень неудачный курс: единственного захода на эту страницу достаточно, чтобы посетитель перестал надолго задерживаться на сайте.
- $\sum$linkUrl=https://vk.com/courses > 8 – вероятно, на эту ссылку кликают посетители, которые не удовлетворены имеющимися на сайте курсами.
- $\sum$lastTrafficSource=saved > 2 – посетители, которые сохранили страничку сайта себе на компьютер, и переходят с неё на сайт, явно заинтересованы в продолжительном обучении.
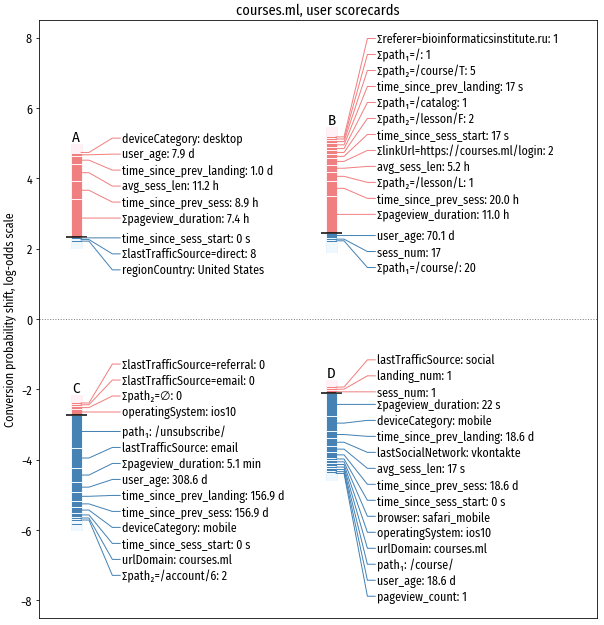
И, в дополнение, образцы scorecards для пары “хороших” и пары “плохих”
посетителей:
Заключение
…We have so much data on the web, almost all of it available for free, that we dive into the the data ocean hoping that magically awesome things will follow. They never do.
Avinash Kaushik.
Основная проблема интернет-аналитики, на мой взгляд, в том, что в ней физически огромное количество данных, но эти данные приносят удивительно мало пользы своим обладателям.
Почему? Потому что это не самые удобные для обработки данные, у них сложная структура, это sparse categorical multivariate time series – подобные типы данных мейнстримовая Machine Learning (а сейчас и AI) индустрия традиционно обходит стороной. Ведь гораздо эффективнее впечатлять инвесторов распознаванием изображений, генерацией музыки или чат-ботами, чем копанием в каких то там логах сессий 🙊
Отчасти поэтому традиционные инструменты интернет аналитики застряли на примитивном уровне и не способны извлечь из данных даже малую часть содержащейся в них полезной информации. За время работы с моделями, описанными в этой статье, я, честно говоря, узнал о поведении посетителей сайтов намного больше, чем за пару лет работы над WebVisor и несколько лет работы в Яндекс.Метрике.
Хочется верить, что разумное применение технологий машинного обучения и AI поможет наконец раскрыть потенциал океана данных интернет-аналитики, и что “awesome things” действительно “will follow”.
