Аудиторию блогера в Инстаграм можно разделить на активную (те, кто лайкают посты) и пассивную (те, кто подписан, но не ставит лайки). Для рекламодателей активная аудитория особенно интересна, поэтому её свойства (соцдем, интересы и т.п.) лучше определять отдельно. Чтобы выделить активную аудиторию, очевидно, необходимо получить лайки к постам. Проблема в том, что у крупных блогеров могут быть миллионы лайков, а Инстаграм за один запрос отдаёт весьма ограниченное количество последних лайков, поэтому получение всех лайков от постов всех блогеров технически затруднительно.
Разумная альтернатива это сэмплирование лайков. Если взять, например сэмпл в 10000 лайков, то свойства аудитории, рассчитанные по этому сэмплу, будут не сильно отличаться от свойств аудитории, посчитанных по миллиону лайков. Но для этого сэмплирование должно быть равномерным, то есть у всех “лайкеров” должны быть примерно одинаковые шансы попасть в сэмпл. Равномерный сэмпл можно получить, если забирать последние лайки поста через некоторые интервалы времени. Но здесь возникает другая проблема: пост собирает основную часть лайков в первые несколько часов своей жизни. Поэтому если не успеть вовремя обнаружить новый пост, основная масса лайков уже не будет доступна, можно будет делать сэмпл только из “хвоста” лайкеров, что приведёт к искажению статистики. Опоздав всего на час, мы пропустим 20-30% всех лайков.
Самый простой вариант борьбы с опозданиями, это проверять, не появились ли новые посты, почаще, например раз в 10 минут. Но этот же вариант и самый неэкономичный по кол-ву запросов в Инстаграм. Блогер вряд ли будет делать посты, когда спит, возможно у него есть любимое время для постинга, любимые дни недели, и т.п. Если понять индивидуальное “расписание” каждого блоггера и подстроить под него наши проверки, можно будет получить хорошую экономию запросов.
Как постят блоггеры
Чтобы понять, есть ли у нас шансы выявить поведенческие паттерны блоггеров,
визуализируем некоторые имеющиеся данные.
Распределение интервалов между постами, I
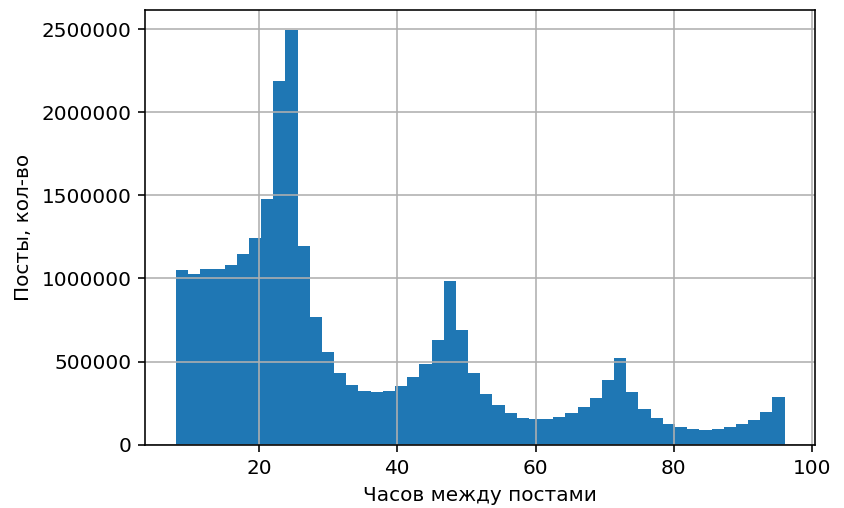
Хорошо видны пики 24-48-72 часа, соответствующие постингу раз в сутки/двое/трое в одно и то же время. То есть у многих блогеров есть “любимое” время постинга, и интервал между их постами получается кратным 24 часам.
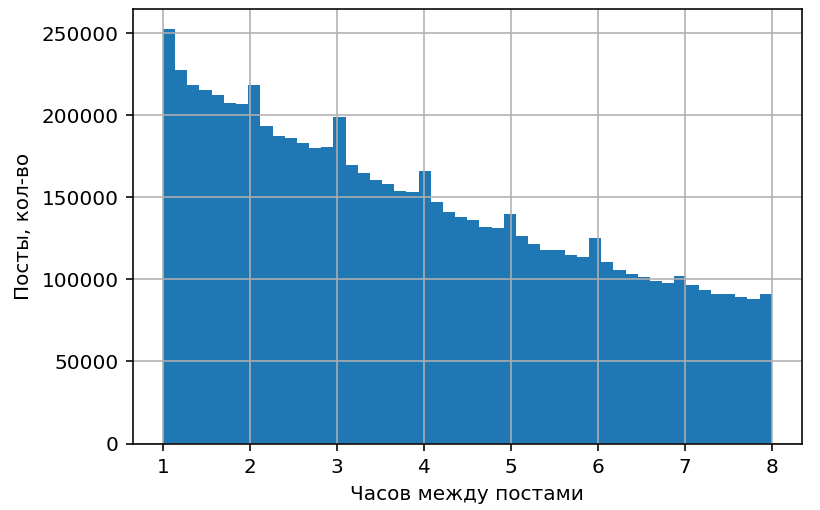
Распределение интервалов между постами, II
На меньшем масштабе заметны пики, соответствующие постингу раз в час или в несколько часов. Возможно, это следы работы сервисов отложенного постинга.
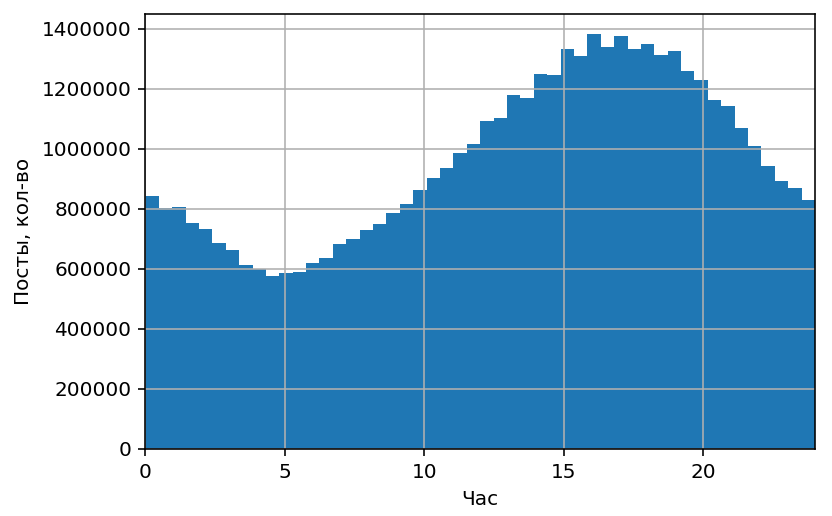
Количество постов по времени суток, по всему Инстаграму.
Хорошо заметны внутрисуточные подъемы и спады активности, связанные с естественными суточными ритмами “сон-бодрствование” и разной активностью в рабочее и нерабочее время.
Аудитория Инстаграма интернациональна и распределена по всему миру по разным часовым поясам. Чтобы лучше понять природу подъемов и спадов, визуализируем аудиторию из разных стран по отдельности:
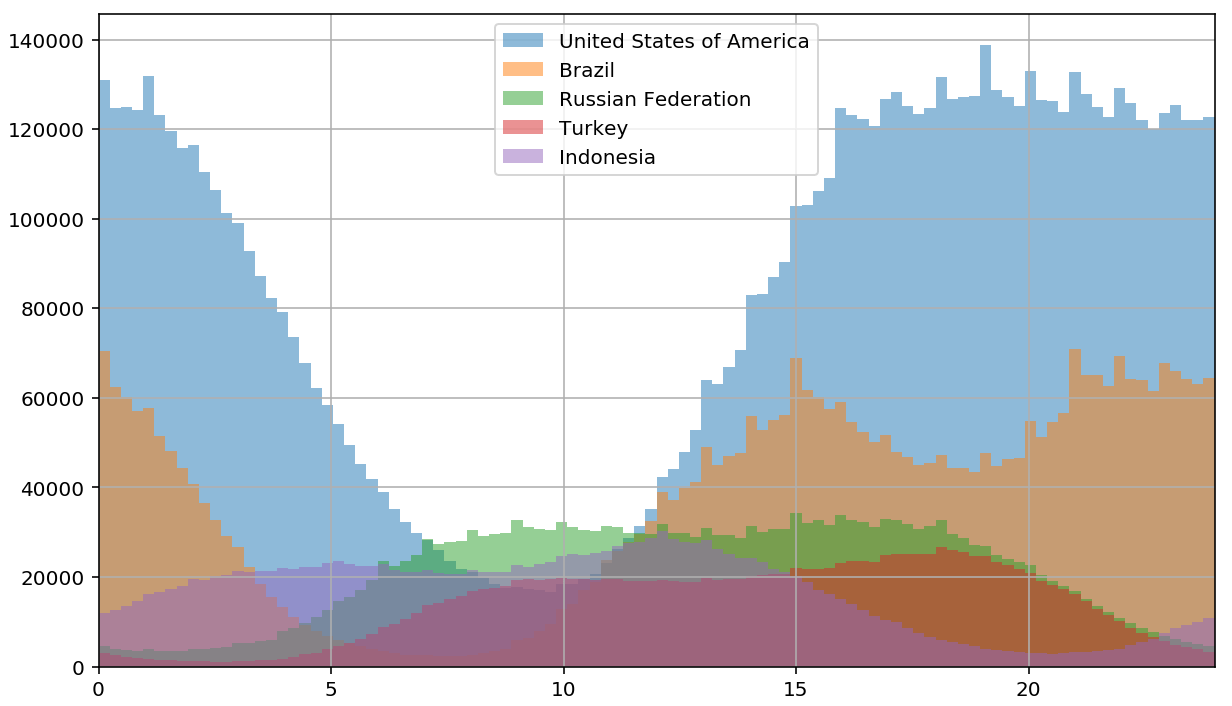
Количество постов по времени суток, раздельно по странам.
На графиках отдельных стран суточная цикличность выражена еще более явно. Также в некоторых странах заметно нарастание активности до начала рабочего дня и после его окончания.
Детализированные паттерны постинга
Визуальный анализ общей активности показывает, что посты распределяются внутри суток неравномерно, есть определенные закономерности. А сейчас от общего анализа перейдем к более подробной детализации, и посмотрим, как делают посты индивидуальные блоггеры.
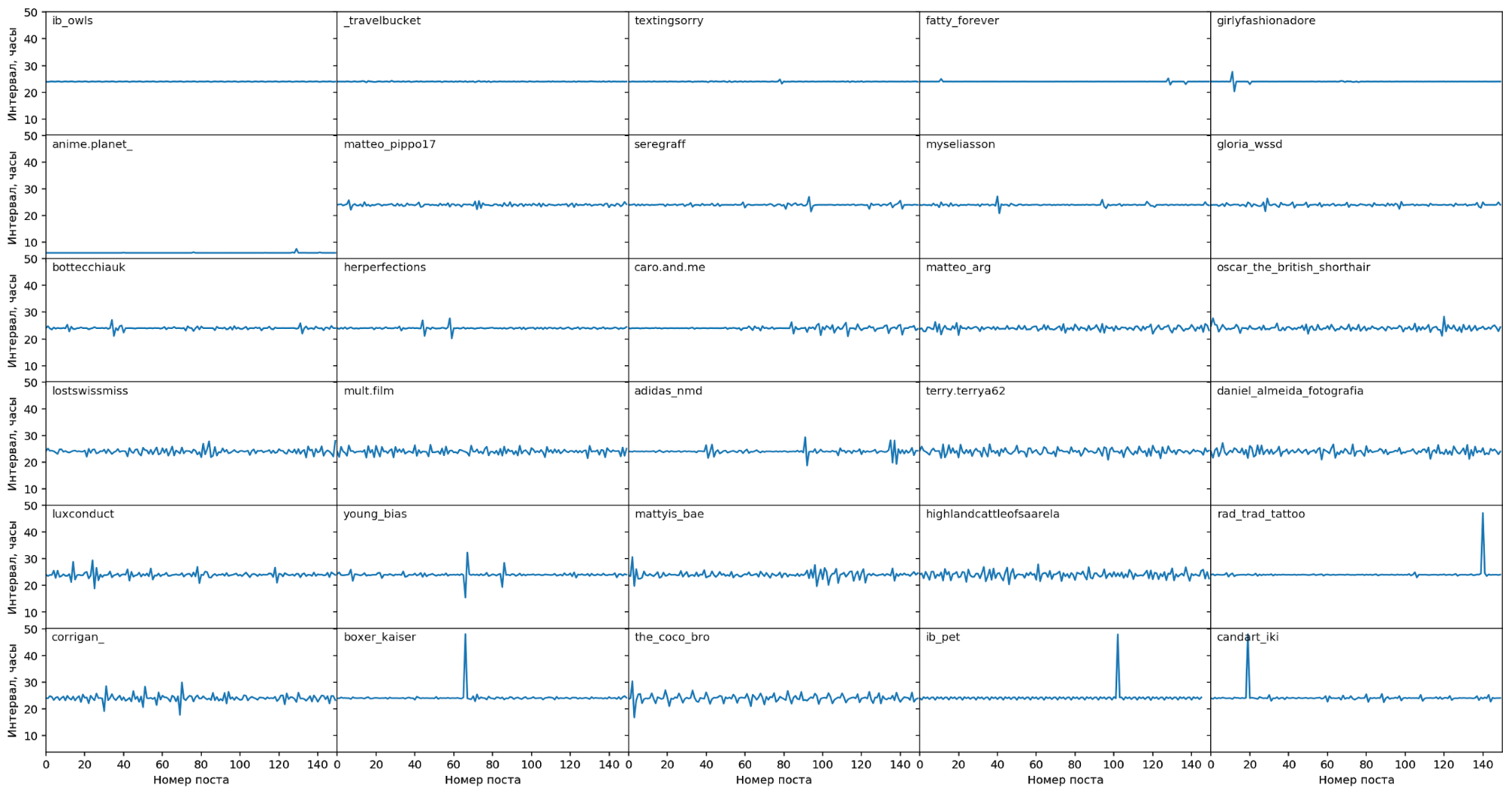
Стабильные блогеры
Сначала посмотрим на “стабильных” блогеров, у которых минимальна
дисперсия интервалов между постами. Видно, что такие блогеры делают посты
в основном строго раз в 24 часа, с небольшими отклонениями:
Нестабильные блогеры
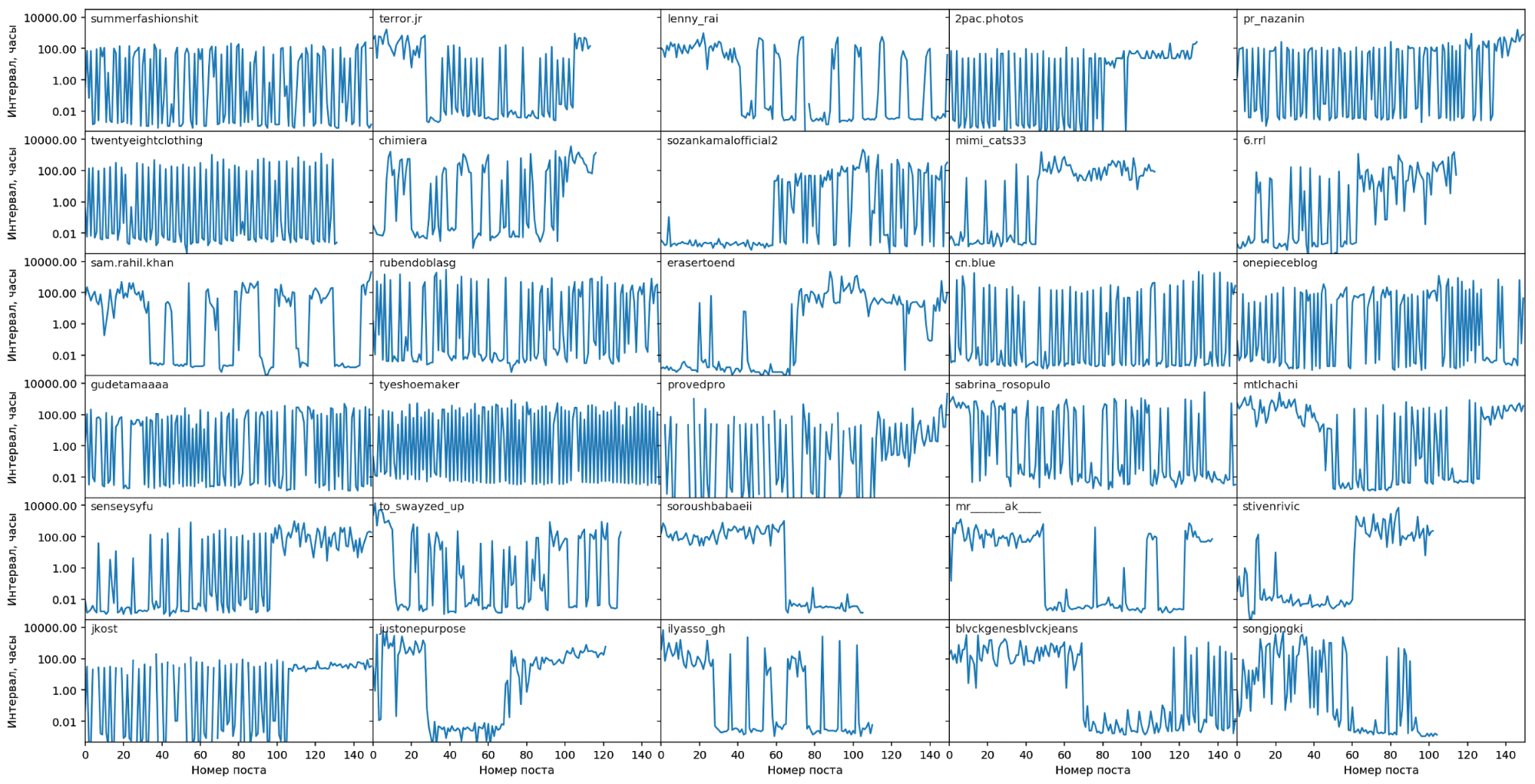
На следующем графике – “нестабильные” блогеры, у которых высокая вариативность
интервалов между постами. В основном это те, кто делает постинг пакетами по 2-3 поста,
с большой паузой между пакетами. Видно, как интервал между постами циклически изменяется от секунд до нескольких суток:
Быстрые блоггеры
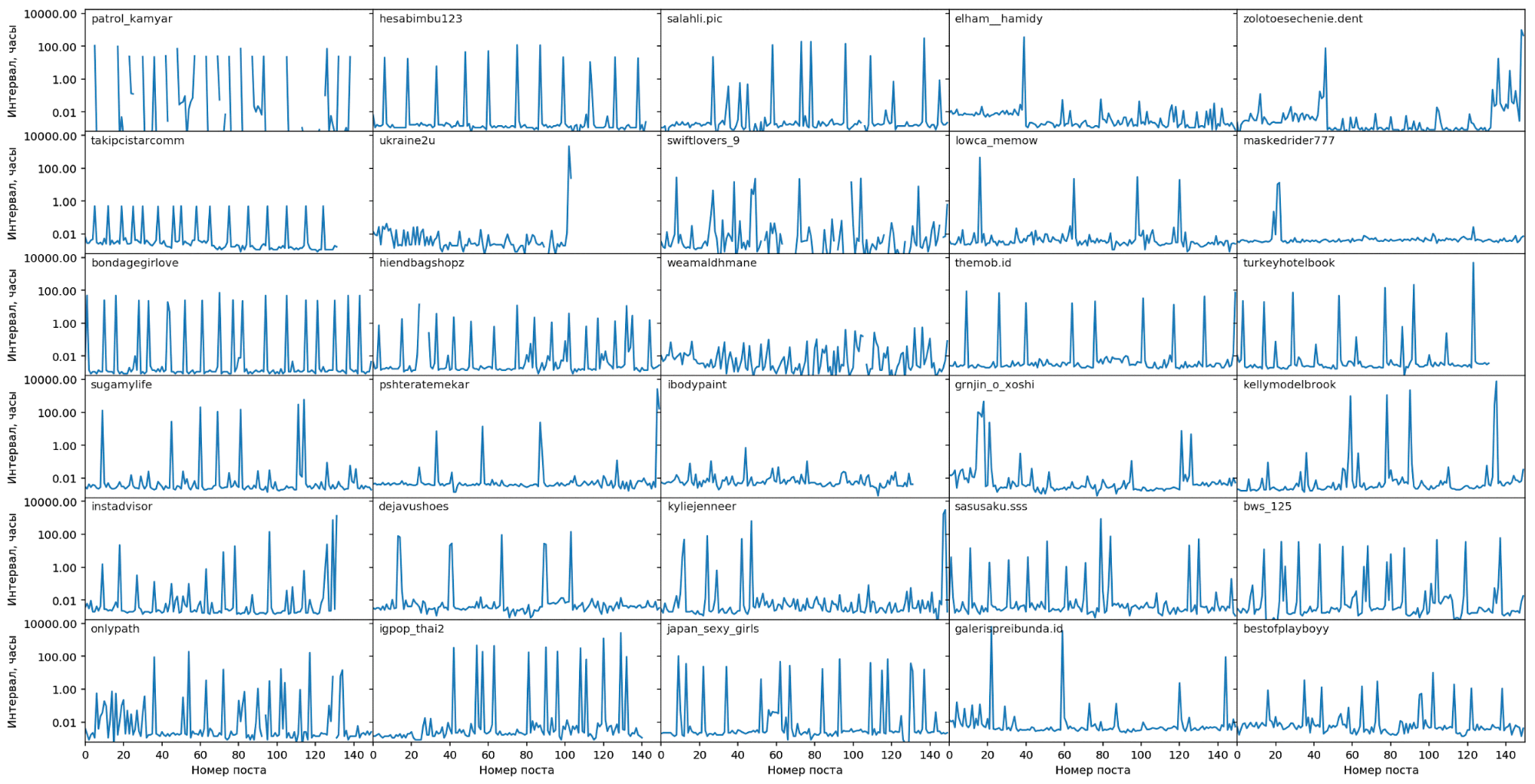
На этом графике блоггеры с минимальным интервалом между постами, т.е.
создающие много постов в час. В основном это аккаунты магазинов,
выкладывающие в Instagram свой товарный каталог. Видны регулярные паузы
между постингами (единичные всплески вверх), по видимому они постят
только в рабочее время, а в нерабочее и по выходным - отдыхают.
Медленные блоггеры
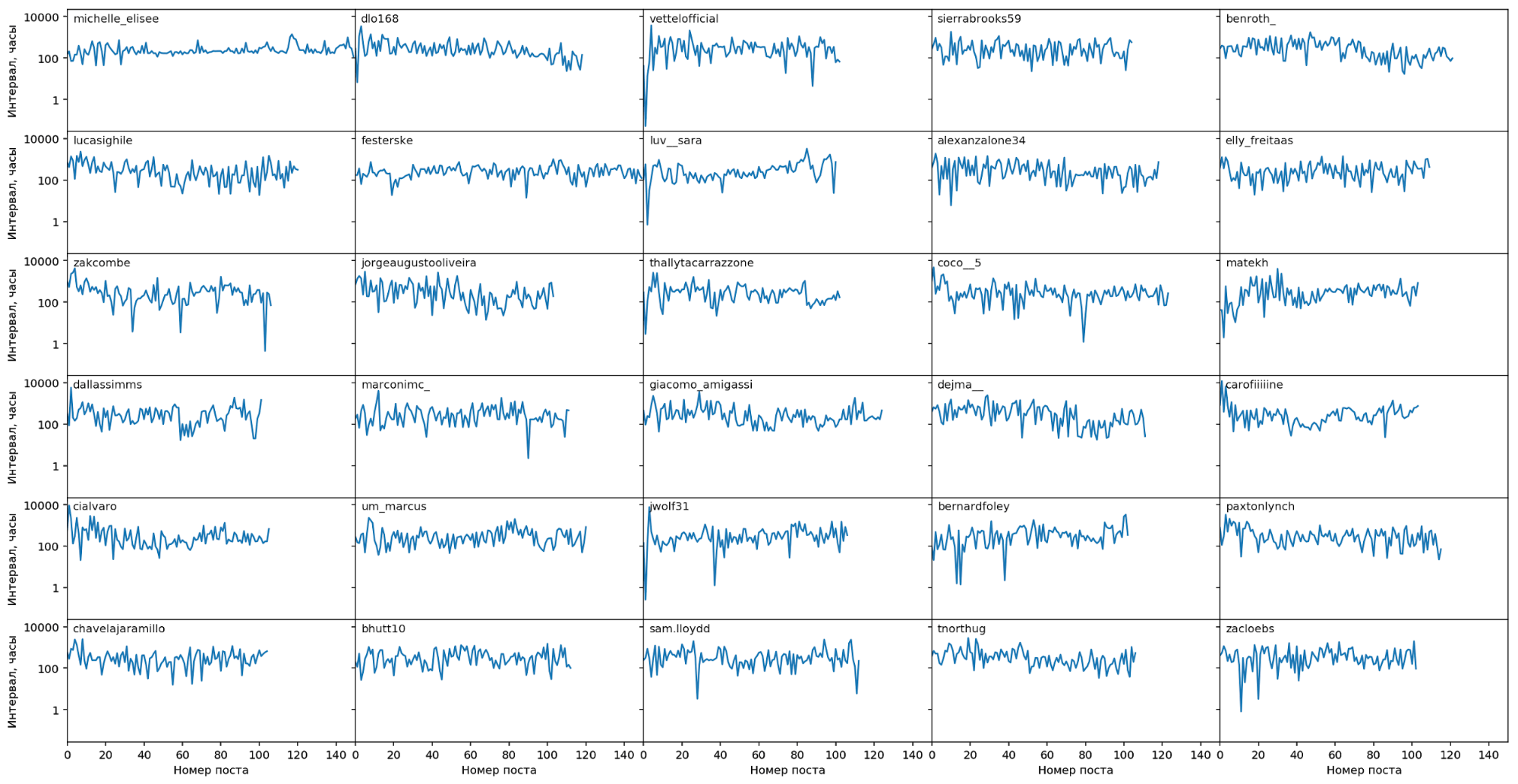
На этом графике блоггеры с максимальным интервалом между постами, т.е. с редкими постами.
Каких либо явных закономерностей здесь не прослеживается:
Итак, мы увидели, что с одной стороны в posting patterns есть множество явных закономерностей, с другой стороны у разных блогеров эти закономерности разные, а у многих вообще отсутствуют. Создать вручную набор правил, который одинаково хорошо подходил бы любому блогеру, не представляется возможным. Решить эту задачу за разумное время можно только с помощью машинного обучения.
Пробуем machine learning
Немного теории
Первый вопрос, который надо задать при разработке machine learning модели – что мы, собственно, хотим предсказать? С первого взгляда кажется, что надо предсказывать время следующего поста. То есть наша модель должна обучиться функции: $$t_{i+1} = f(t_0, \dots, t_{i})$$
где $t_0, \dots, t_{i}$ это история времени предыдущих постов, а $t_{i+1}$ это время следующего поста, которое мы хотим предсказать.
Но на самом деле это плохая идея. Предсказывать точное время следующего поста это все равно, что предсказывать итог бросания монетки. Если монета честная, то мы знаем, что в среднем итог бросков будет 50/50. Но предсказать итог каждого конкретного броска невозможно. Та же ситуация с блогером: допустим, мы знаем, что он предпочитает делать посты по вечерам. Но в конкретный день он может не сделать пост, потому что находится в поездке, или сделать пост позже обычного, потому что у него были другие дела, или наоборот сделать сразу два поста. Чтобы предсказывать точное время, нам потребовалось бы знать множество фактов из жизни блогера, которых у нас нет.
Поэтому лучше предсказывать вероятность того, что блогер сделает пост в определённом интервале времени. Вероятность единичных событий, происходящих на фиксированном отрезке времени, в простейшем случае описывается распределением Пуассона: $$\Pr(k)=\frac{\lambda^k}{k!}e^{\lambda}$$
- $k$ – наблюдаемое количество событий за единицу времени (в нашем случае события это посты, а за единицу времени можно взять, например, сутки);
- $\lambda$ – математическое ожидание количества событий за единицу времени, т.е. среднее количество событий. Этот параметр еще называют интенсивностью.
Допустим, блогер делает в среднем 3 поста в сутки ($\lambda=3$). Тогда, согласно распределению Пуассона, у нас получаются следующие вероятности увидеть $k$ постов за один конкретный день:
- вероятность увидеть 0 постов (т.е. ни одного): $$\Pr(k=0)=\frac{2^0}{0!}e^{-3}=\frac{1}{1}e^{-3}\approx0.05$$
- вероятность увидеть 1 пост: $$\Pr(k=1)=\frac{3^1}{1!}e^{-3}=\frac{3}{1}e^{-3}\approx0.15$$
остальные значения выведены на график:
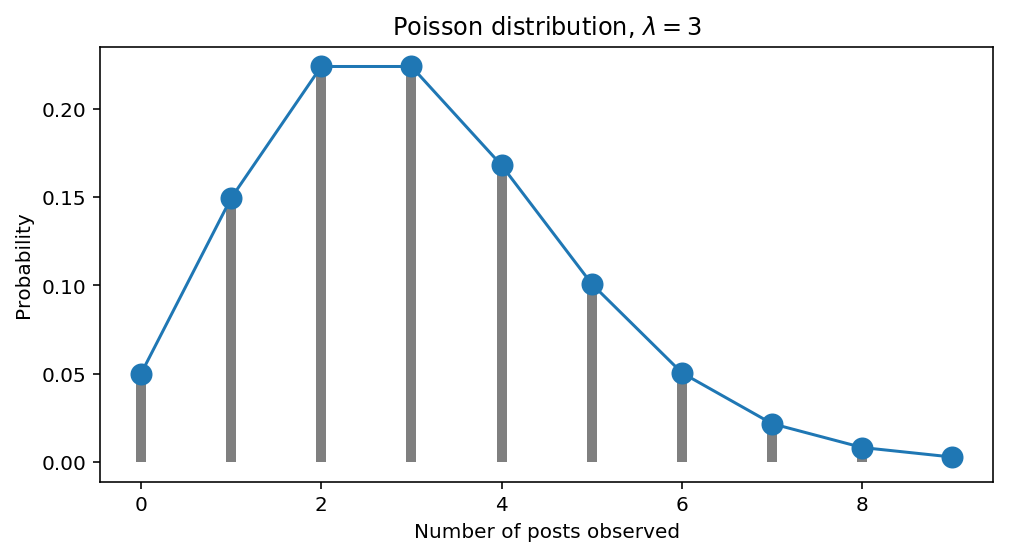
Если бы блоггеры всегда делали посты с одинаковой интенсивностью, т.е. соблюдалось бы условие $\lambda=const$, то на этом можно было бы закончить наш анализ, и даже не понадобилось бы машинное обучение. Но в реальной жизни интенсивность все время изменяется. Блогер может открыть для себя новую тематику, вдохновиться ею, и начать делать посты в несколько раз чаще, чем обычно. Или наоборот, блогер может забросить свой аккаунт, переключившись на что-то другое, или уехать в отпуск, и вообще перестать делать посты. В этом случае интенсивность будет стремиться к нулю. Таким образом, в реальной жизни это не константа, а функция от времени:
$$\lambda=f(t)$$
Наша задача – найти эту функцию, тогда мы сможем оценить вероятность появления нового поста в произвольный момент времени, и смоделировать поведение блогеров.
От теории к практике
Построим модель, которая обучится целевой функции: $$\lambda=f(t, h)$$ где $h$ – история предыдущих постов блогера, $t$ – относительное время, прошедшее с момента последнего поста.
Будем предсказывать интенсивность для следующих 24 часов после момента времени $t$. Для обучения необходимо задать loss function, показывающую, насколько хорошо работают наши предсказания. Будем использовать negative log likelihood:
$$loss=-\log(Pr_{\lambda}(X=x\mid t))$$ это вероятность наблюдения в течение 24 следующих часов после момента времени $t$ количества постов, равного $x$, для распределения Пуассона, характеризуемого параметром $\lambda$. Количество постов берется из реальных данных. Чем точнее мы предсказали значение $\lambda$, тем выше будет вычисленная по реальному количеству постов вероятность, и тем меньше будет loss.
Для обучения будем использовать deep learning model, состоящую из Recurrent Neural Network и нескольких fully connected layers. На входы RNN подаётся история предыдущих постов блогера, на вход fully connected layers блока – состояния на выходе из RNN и время $t$.
Посмотрим, что получается в результате обучения, на примерах постов отдельных блоггеров. Голубым обозначена предсказанная интенсивность, оранжевыми треугольниками и вертикальными линиями - моменты времени, когда происходили посты. В идеале в те моменты, когда происходил постинг, предсказанная интенсивность должна быть высокой, а в моменты, когда постов не было – низкой:

Видно, что при повышении частоты постов предсказанное значение параметра $\lambda$, как и ожидалось, растет, а при отсутствии постов падает. Когда блогер перестал делать новые посты, значение $\lambda$ упало практически до нуля. В момент, когда происходит новый пост после долгой паузы, значение $\lambda$ скачкообразно повышается, т.к. модель видит, что блогер still alive, и начинает ожидать от него потока новых постов.
Фактически, мы смоделировали самовозбуждающийся Hawkes process, не используя при этом никакой сложной параметризованной математики – deep learning модель сама обучилась всем закономерностям!

На втором примере модель, пронаблюдав историю постов в первые три месяца, выявила “любимые дни” блогера, когда он делает посты. Соответственно, предсказанная интенсивность начинает повышаться заранее, в ожидании того, что блогер скоро сделает пост. Даже когда постов нет, ожидаемая интенсивность все равно циклически повышается и понижается.

Как видим, наша модель вполне способна выявить поведенческие паттерны блогера, и предсказывать вероятность постов во времени в соответствии с этими паттернами.
Модель для реального применения
Модель, предсказывающая интенсивность (т.е. параметр $\lambda$ для распределения Пуассона), хороша с теоретической точки зрения. Но она не дает прямого ответа на вопрос, который нас интересует на практике: когда надо проверять, не появился ли новый пост? Чтобы получить ответ на этот вопрос, необходимо проинтегрировать функцию интенсивности:
$$\Lambda=\int_{t_{0}}^{t’} \mathrm\lambda(t)\,\mathrm{d}t$$
где $t_0$ – текущее время, $t’$ – предполагаемое время проверки.
Сначала надо положить $t’=t_0$, и потом постепенно увеличивать $t’$, пока вычисленное значение интеграла не станет больше некоторого заранее выбранного порога. Понятно, что вычисление интеграла числовой аппроксимацией по отдельным точкам, в которых модель рассчитала предсказания для $\lambda$, это неточная, неудобная и ресурсоемкая процедура. Поэтому для реального использования лучше сделать другую модель, которая сразу будет предлагать время проверки.
Как и с предыдущей моделью, нам надо определить, какая будет loss function. Необходимо соблюсти одновременно два условия, противоречащие друг другу: с одной стороны, надо делать проверки как можно реже, чтобы не генерировать большое кол-во запросов к Instagram. С другой стороны, надо минимизировать опоздания, т.е. обнаруживать пост в тот момент, когда он еще не накопил много лайков. Для минимизации опозданий надо наоборот проверять как можно чаще. Наша loss function должна выражать баланс между этими двумя условиями.
Для начала разберемся с тем, как оценивать опоздания. Рост количества лайков в посте происходит нелинейно,
вначале он очень быстрый, потом затухает, и к истечению двух дней с момента публикации поста рост практически прекращается.
Прирост лайков в разных постах можно визуализировать таким суммарным графиком:
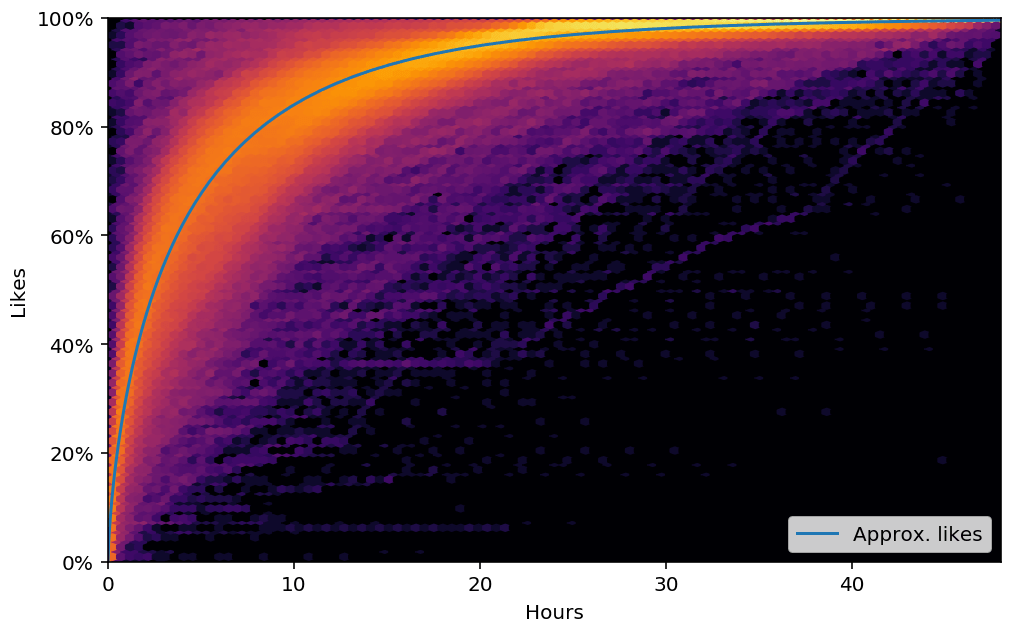
Приблизительно смоделировать зависимость кол-ва лайков от времени можно формулой: $$likes=1-e^{-\left(\frac{t}{\alpha}\right)^{\beta}}$$ где $t$ – время в часах; $\alpha, \beta$ – подбираемые эмпирические коэффициенты. Для нашего случая $\alpha=4.2, \beta=0.7$. Смоделированные значения показаны голубой линией на графике. Используя эту формулу, мы можем оценить опоздание, как долю от общего кол-ва лайков, которую мы пропустили. Таким образом, опоздание будет величиной в интервале $[0,1]$. Это первая часть нашей loss function.
Второй частью будет оценка частоты проверок – инвертированная длина предсказанного интервала между текущим временем и временем следующей проверки. Чем длинее эти интервалы, тем меньше будет проверок. Итоговый loss складывается из потерь по лайкам $loss_{l}$ и потерь по опозданиям $loss_{f}$:
$$loss = loss_{l} + k \cdot loss_{f}$$
где $k$ это коэффициент, регулирующий баланс между частотой проверок и размером опозданий. Выставляется вручную, исходя из бизнес соображений: какой есть бюджет на проверки и насколько критичны опоздания. При увеличении коэффициента частота проверок снижается и опоздания растут, при уменьшении наоборот.
$$loss_{f} = \hat{t}^{-1}$$
$$loss_{l} = \sum_{i=1}^{n} loss_{p_i}$$
$$loss_{p_i} =
\begin{cases}
1-\exp\left(-\left(\frac{\hat{t}-t^{post}_i}{\alpha}\right)^{\beta}\right) & \quad \text{if } \hat{t}-t^{post}_i > 0\\
0 & \quad \text{otherwise}
\end{cases}
$$
- $\hat{t}$ – предсказанный временной интервал от текущего времени до следующей проверки.
- $n$ – количество будущих постов, т.е. постов, будут сделаны после текущего времени.
- $t^{post}_i$ – временной интервал от текущего времени до $i$-го будущего постоа.
- $loss_{p_i}$ – потери по лайкам для каждого будущего поста. Потери учитываются, только если произошло опоздание, т.е. для поста выполнятся условие $\hat{t}-t^{post}_i > 0$, в противном случае потери равны нулю.
- $\alpha, \beta$ – коэффициенты для моделирования динамики лайков, о которых говорилось выше.
Во время обучения будем каждый раз выбирать случайным образом момент текущего времени внутри истории постов аккаунта, и предсказывать время следующей проверки относительно этого текущего времени. Таким образом, после достаточно длительного обучения, мы попадем почти в каждый интервал между постами, и сделаем предсказания для множества разных мест в истории.
Результаты
Посмотрим, какие результаты дает обученная модель. Будем визуализировать на timeline одновременно и реальные посты, и точки проверок, предсказанные нашей моделью. В идеале, если бы нам было известно, когда блогер сделает пост, каждая проверка была бы сразу после появления нового поста, а в интервалах между постами проверок не было бы вообще, или они были бы очень редкими. Но этот идеал, как уже обсуждалось в начале этой статьи, недостижим. С другой стороны, можно вообще не применять никаких моделей, и просто проверять, например раз в час, не появились ли у блогера новые посты. Тогда проверки будут равномерно распределены в интервалах между постами, но будет много лишних проверок.
Проверки, полученные с помощью нашей модели, должны быть где-то между этими двумя крайними случаями. Т.е. на временных интервалах, где вероятность нового поста мала, проверки должны быть редкими, а на интервалах, где велика вероятность обнаружить новый пост, проверки должны быть более частыми.
Будем отображать проверки в виде светло-зеленых маленьких точек, а посты в виде более крупных точек,
окрашенных в цветовой шкале от синего до желтого, в зависимости от того,
какое количество лайков мы пропустили из-за опоздания:

Также надо помнить, что лайки нарастают очень быстро, при опоздании всего на 10 минут мы пропускаем 10% лайков, при опоздании на полчаса – 20% лайков, при опоздании на час – 30% лайков.
Посмотрим на предсказания нашей модели для блогеров из тестовой выборки (т.е. блоггеров, которых модель не видела во время обучения):

На первой диаграмме показана вся история одного блогера. По оси Y - интервалы между проверками, т.е. чем выше зеленая точка, тем больше интервал. Видно, что в начале истории модель адаптируется к поведению блогера, наблюдаются довольно сильные опоздания, и короткие интервалы между проверками. Потом, по мере накопления информации о привычках блогера, проверки становятся более редкими и более точными.

Рассмотрим ещё один аккаунт. На первом графике видно, как модель постепенно увеличивает интервал между проверками (зеленые точки уходят выше), если блогер не делает новых постов. Действительно, зачем часто проверять аккаунт, если он ничего не постит?


Успешная работа модели подтверждается не только визуально, но и цифрами. Если интервалы между проверками задаются нашей моделью, то для получения того же среднего процента пропущенных лайков (~15%) требуется сделать в 2-4 раза меньше проверок по сравнению с baseline. За baseline принимаются равномерные проверки раз в N минут. Если же наоборот зафиксировать кол-во проверок и сравнивать процент пропущенных лайков, то у модели он будет в 1.5-2 раза меньше, чем у baseline.
