В ходе работы над последним проектом мне понадобилось в промышленных
масштабах генерировать сэмплы из бета-распределения. Первое что пришло
в голову, это scipy.stat, тем более там есть куча дополнительных
возможностей: и CDF, и квантили, и MLE, и всё, что душа пожелает. Но довольно
быстро я понял, что scipy нетороплив, и генерация нескольких
миллиардов сэмплов затянется на часы, а то и на дни. Стал искать
альтернативные варианты и хочу теперь поделиться найденным.
numpy.random
Сначала выяснилось, что numpy.random умеет генерировать не только
равномерные случайные числа, но и сэмплы из распределений. И делает
это бодрее, чем scipy.stat, особенно на небольших выборках: по видимому,
у scipy.stat большие накладные расходы на каждый вызов.
mkl_random
Совершенно случайно наткнулся на возможность генерации сэмплов в Intel MKL. MKL это вообще такой подводный айсберг, в котором есть много всякого хорошего, но мало кто об этом знает. Почему то Intel его не продвигает, или просто не умеет продвигать?
Ребята крайне серьезно подошли к вопросу генерации сэмплов, для каждого распределения есть замеры производительности при разных значениях параметров распределений и при разных настройках базового генератора случайных чисел. Алгоритмически там тоже всё круто, для бета распределения в зависимости от параметров распределения происходит переключение аж между четырьмя различными алгоритмами генерации сэмплов: у каждого алгоритма есть своя оптимальная область параметров, в которой алгоритм даёт наилучшее быстродействие и качество.
В Питоне генератор сэмплов доступен как библиотека mkl_random,
причём есть еще такая инкарнация, которая при установке
попытается притащить с собой весь дистрибутив Intel Python.
Потом выяснилось, что мне вообще ничего не надо устанавливать, mkl_random по видимому идёт в стандартной
поставке Conda. Ещё mkl_random прорастает в numpy в виде пакета numpy.random_intel,
но происходит это всегда, или при особом положении звёзд, я так и не понял.
В плане производительности всё превосходно, по сравнению с numpy.random разница примерно на порядок.
Собственно, это лучший вариант для генерации сэмплов на CPU. Ещё одна приятная
возможность – можно менять базовый алгоритм генерации случайных чисел,
есть быстрые генераторы, оптимизированные под процессоры с поддержкой SIMD.
Переключение генератора совмещено с seed:
import mkl_random
# SIMD-oriented Fast Mersenne Twister (SFMT)
mkl_random.seed(None, 'SFMT19937')
cupy.random
Генерация массива сэмплов это по своей природе очень хорошо параллелизуемая операция,
поэтому я стал искать реализацию для GPU. Реализация нашлась в лице пакета
cupy , имплементирующего подмножество функций numpy на GPU.
Подмножество, кстати, весьма впечатляющее, и numpy.random тоже в него входит
в виде реинкарнации cupy.random. Хочу выразить респект разработчикам
Chainer/Cupy, которые не стали заново имплементировать функциональность numpy в виде собственного велосипеда с блэкджеком,
как это сделали Tensorflow и Pytorch, а сохранили совместимость с оригинальным numpy на уровне API.
Скорость работы просто фантастическая. На GTX1080Ti cupy генерирует более полумиллиарда сэмплов из бета распределения в секунду! Это больше, чем способны переварить остальные компоненты моего проекта. Апгрейдом до cupy вопрос скорости генерации сэмплов был полностью закрыт.
Не обошлось без ложки дёгтя: в cupy некорректно работает обновление seed после генерации сэмпла. Seed хранится как 64-битный float (размером до 10308), и выставляется на старте обычно в достаточно большое число. После генерации сэмпла к нему добавляется целое, которое этому float-у как слону дробина, и не меняет его ни на единый бит. В итоге cupy каждый раз выдаёт один и тот же сэмпл. Пришлось выставлять seed вручную.
Остальное
Из любопытства прогнал через бенчмарк также высокоуровневые библиотеки, умеющие генерировать сэмплы из распределений: PyMC3, Pytorch и Tensorflow.
PyMC3 показал стабильно худшие результаты среди всего, что я тестировал. Как это ни печально, библиотека, основная работа которой состоит в сэмплировании, делает это хуже всех остальных. Видимо сказывается возраст Theano, на котором основана вся функциональность PyMC3.
PyTorch при работе на CPU показал себя средне (на Бета распределении вообще провал), но при работе на GPU вполне конкурировал с cupy, иногда отставал, иногда обгонял.
Tensorflow, как выяснилось, не умеет сэмплировать на GPU. Если запускать всё с дефолтными настройками, то он будет делать вид, что работает на GPU, но на самом деле будет сэмплировать медленнее по сравнению с честным запуском на CPU, потому что будет гонять данные туда-сюда. При сэмплировании на CPU показал себя хорошо, стабильное второе место после mkl_random, но большие накладные расходы на каждый вызов.
Результаты тестирования
Я тестировал быстродействие сэмплеров на трех распределениях, с параметрами, близким к используемым в моём проекте:
- Бета распределение с параметрами $\alpha=1$, $\beta=100$
- Распределение Пуассона с параметром $\lambda=10$
- Нормальное распределение со стандартными параметрами $\mu=0$, $\sigma=1$,
тестировать с другими смысла нет, т.к. такие сэмплы получаются из стандартных простым
умножением.
Для cupy запускалось два варианта тестов, один с копированием результатов
с GPU на хост, второй без копирования (т.к. результаты могут обрабатываться
и на GPU). Вариант без копирования называется cupy_nht (No Host Copy).
Разница между ними до 2х и более раз. GPU-тесты PyTorch запускались всегда
с копированием на хост.
Тесты проводились с переменным размером батча (т.е. сколько сэмплов генерируется за один вызов), варьирующимся от десяти до миллиона. Быстродействие всех библиотек сильно зависит от этого размера.
Результаты приводились к количеству сэмплов, генерируемому в секунду. Числа в таблицах измеряются в миллионах сэмплов в секунду.
Бета распределение
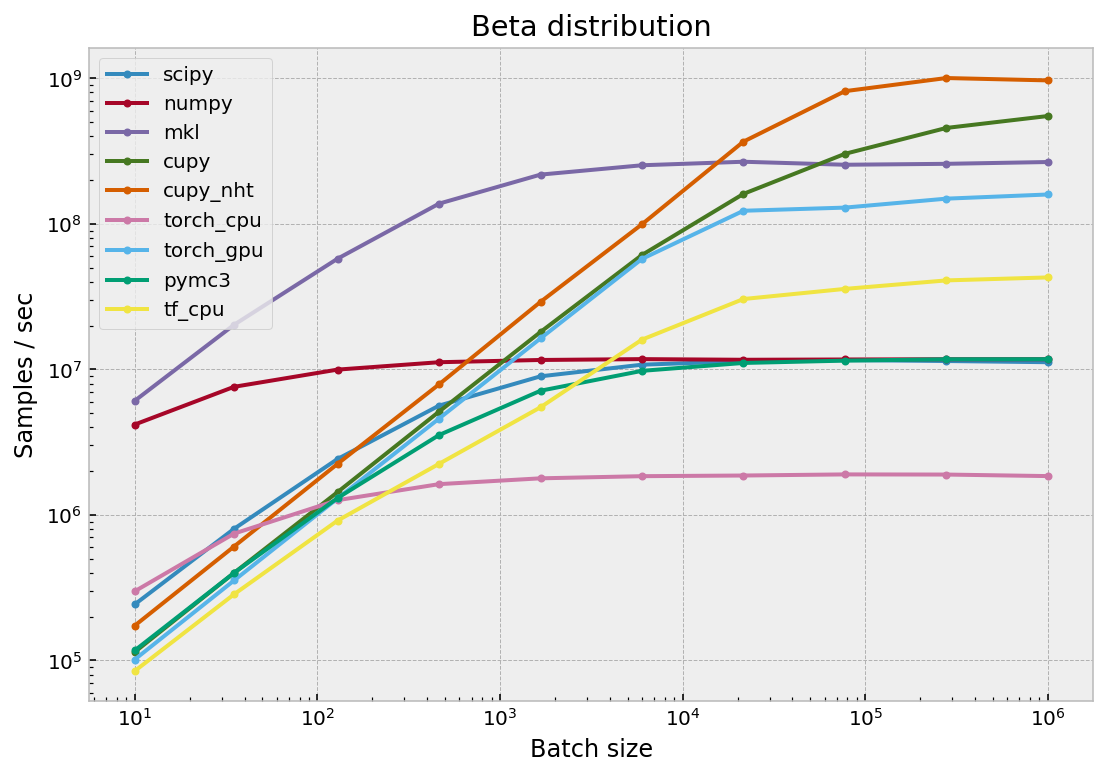
| batch | scipy | numpy | mkl | cupy | cupy_nht | torch_cpu | torch_gpu | pymc3 | tf_cpu |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 0.2 | 4.2 | 6.1 | 0.1 | 0.2 | 0.3 | 0.1 | 0.1 | 0.1 |
| 35 | 0.8 | 7.6 | 20.3 | 0.4 | 0.6 | 0.7 | 0.4 | 0.4 | 0.3 |
| 129 | 2.4 | 10.0 | 57.6 | 1.4 | 2.2 | 1.3 | 1.3 | 1.3 | 0.9 |
| 464 | 5.6 | 11.2 | 137.7 | 5.1 | 7.9 | 1.6 | 4.6 | 3.5 | 2.2 |
| 1668 | 9.0 | 11.6 | 218.1 | 18.1 | 29.1 | 1.8 | 16.3 | 7.1 | 5.5 |
| 5994 | 10.8 | 11.8 | 252.8 | 61.1 | 99.4 | 1.8 | 57.4 | 9.8 | 16.0 |
| 21544 | 11.4 | 11.6 | 267.3 | 160.7 | 367.4 | 1.9 | 123.1 | 11.1 | 30.5 |
| 77426 | 11.6 | 11.7 | 254.9 | 302.9 | 816.6 | 1.9 | 129.4 | 11.5 | 35.7 |
| 278255 | 11.4 | 11.7 | 258.7 | 456.3 | 1005.3 | 1.9 | 149.1 | 11.7 | 40.9 |
| 1000000 | 11.2 | 11.7 | 266.1 | 551.0 | 968.3 | 1.8 | 159.2 | 11.8 | 42.9 |
Распределение Пуассона
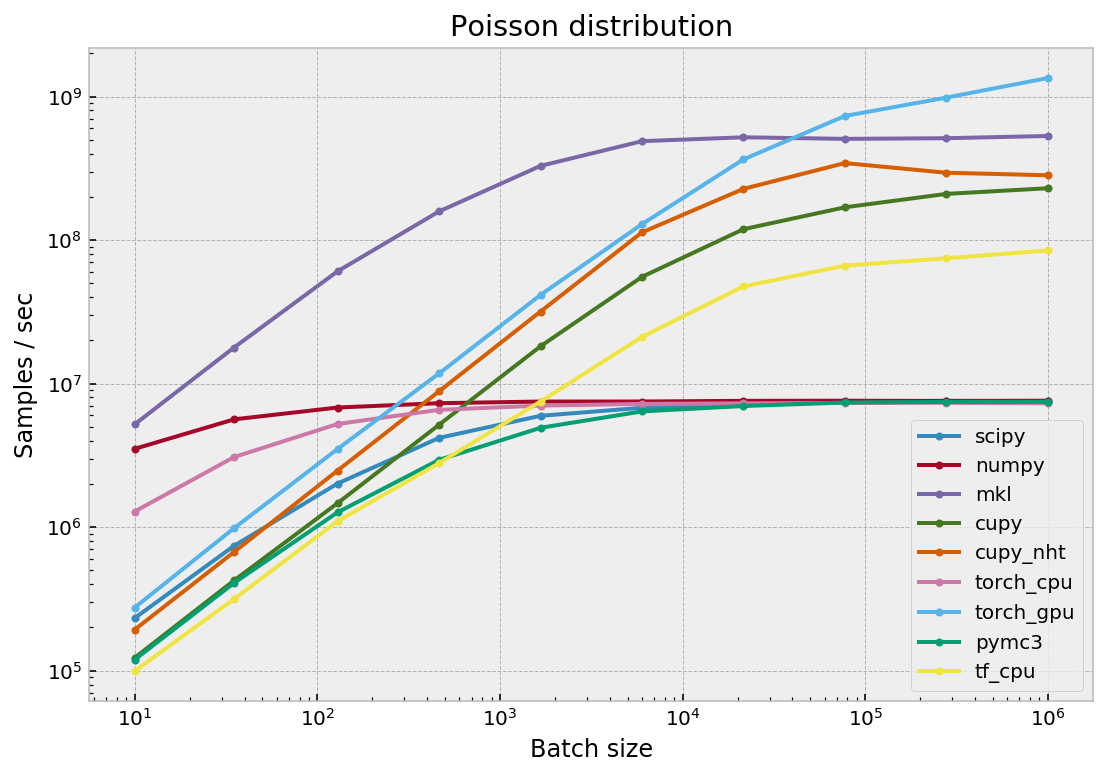
| batch | scipy | numpy | mkl | cupy | cupy_nht | torch_cpu | torch_gpu | pymc3 | tf_cpu |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 0.2 | 3.5 | 5.2 | 0.1 | 0.2 | 1.3 | 0.3 | 0.1 | 0.1 |
| 35 | 0.7 | 5.6 | 17.8 | 0.4 | 0.7 | 3.1 | 1.0 | 0.4 | 0.3 |
| 129 | 2.0 | 6.8 | 60.6 | 1.5 | 2.5 | 5.2 | 3.5 | 1.3 | 1.1 |
| 464 | 4.2 | 7.3 | 158.4 | 5.2 | 8.8 | 6.6 | 11.8 | 2.9 | 2.8 |
| 1668 | 6.0 | 7.5 | 328.9 | 18.2 | 31.8 | 7.0 | 41.5 | 4.9 | 7.5 |
| 5994 | 6.8 | 7.5 | 489.0 | 55.4 | 113.1 | 7.2 | 129.1 | 6.4 | 21.2 |
| 21544 | 7.2 | 7.6 | 520.4 | 119.1 | 227.5 | 7.3 | 365.1 | 7.0 | 47.6 |
| 77426 | 7.5 | 7.6 | 507.3 | 169.2 | 344.1 | 7.3 | 732.6 | 7.4 | 66.4 |
| 278255 | 7.6 | 7.6 | 512.9 | 209.9 | 294.7 | 7.3 | 983.8 | 7.5 | 74.7 |
| 1000000 | 7.5 | 7.6 | 531.4 | 229.7 | 282.9 | 7.3 | 1346.7 | 7.5 | 84.7 |
Нормальное распределение
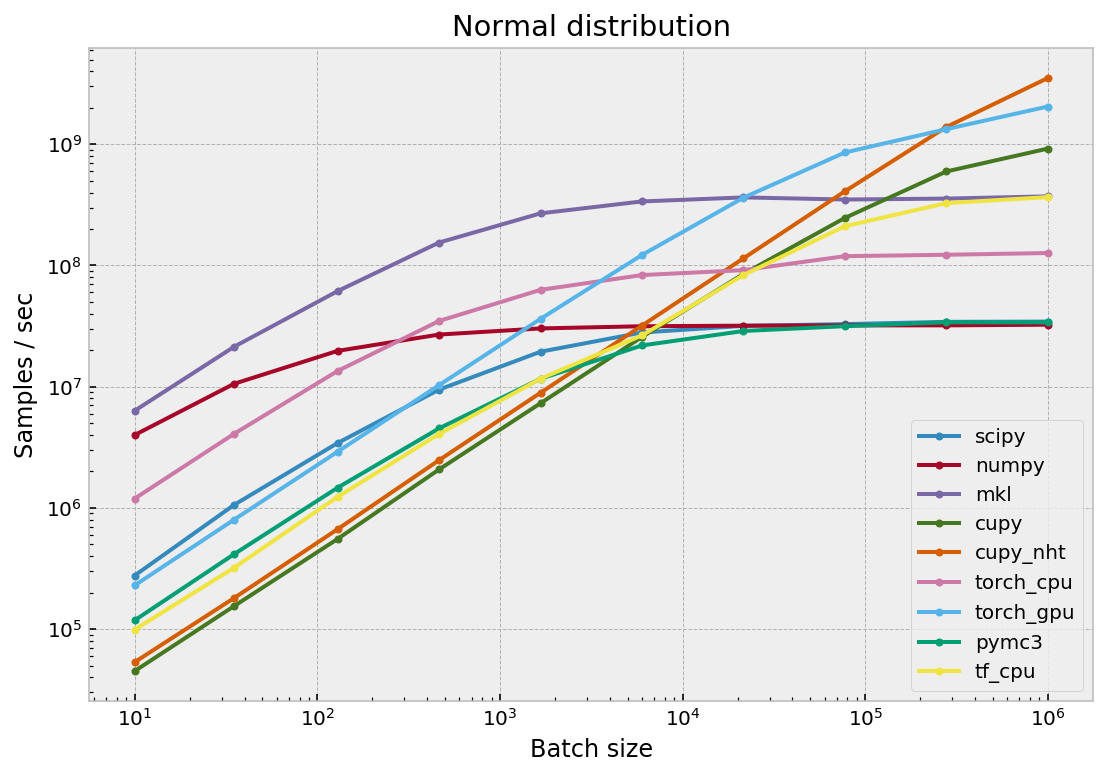
| batch | scipy | numpy | mkl | cupy | cupy_nht | torch_cpu | torch_gpu | pymc3 | tf_cpu |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 0.3 | 4.0 | 6.3 | 0.0 | 0.1 | 1.2 | 0.2 | 0.1 | 0.1 |
| 35 | 1.1 | 10.6 | 21.3 | 0.2 | 0.2 | 4.1 | 0.8 | 0.4 | 0.3 |
| 129 | 3.4 | 19.7 | 61.4 | 0.6 | 0.7 | 13.5 | 2.9 | 1.5 | 1.2 |
| 464 | 9.5 | 26.9 | 154.6 | 2.1 | 2.5 | 34.8 | 10.3 | 4.5 | 4.1 |
| 1668 | 19.4 | 30.2 | 269.3 | 7.3 | 8.9 | 62.9 | 36.3 | 11.6 | 11.6 |
| 5994 | 28.0 | 31.5 | 337.7 | 25.7 | 31.9 | 83.4 | 122.1 | 21.9 | 26.5 |
| 21544 | 31.7 | 31.9 | 364.5 | 85.2 | 114.5 | 91.5 | 362.5 | 28.8 | 83.3 |
| 77426 | 32.8 | 32.0 | 350.2 | 246.8 | 409.4 | 119.4 | 855.8 | 31.6 | 211.0 |
| 278255 | 34.3 | 32.1 | 356.4 | 596.5 | 1389.0 | 122.6 | 1333.1 | 34.0 | 327.0 |
| 1000000 | 34.4 | 32.5 | 371.9 | 921.5 | 3521.7 | 126.7 | 2049.5 | 33.9 | 366.5 |
Тестирование проводилось на CPU i7-6850K (Broadwell E, 6 cores, 12 threads) и GPU GTX1080Ti.
Код, всех тестов доступен в GitHub: https://gist.github.com/Arturus/dd5397e5cba3e4c05745811371406d83
